
[ad_1]
In the previous handful of many years, a concentration in language modelling has been on strengthening performance via expanding the selection of parameters in transformer-centered products. This solution has led to extraordinary final results and condition-of-the-art efficiency throughout numerous natural language processing duties.
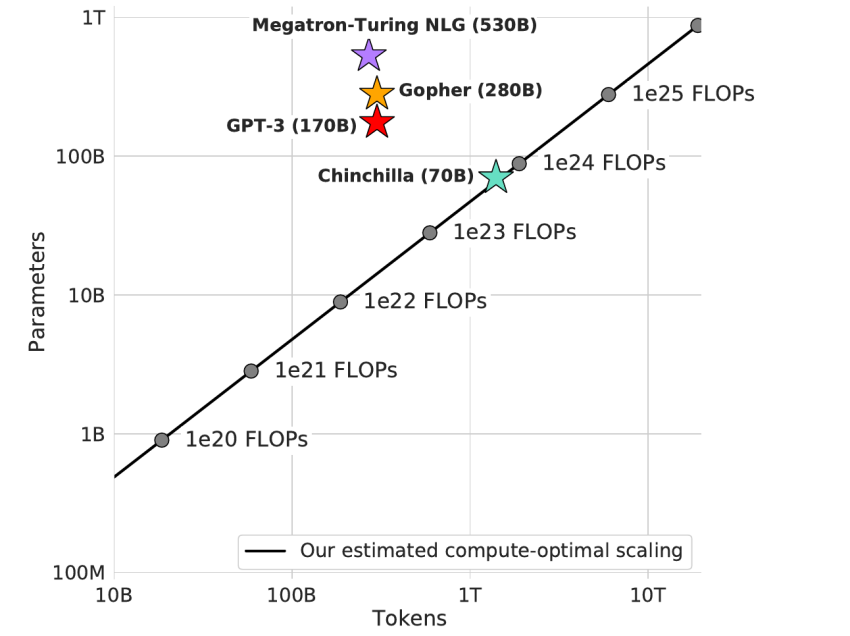
We also pursued this line of investigate at DeepMind and not too long ago showcased Gopher, a 280-billion parameter product that founded primary general performance on a wide vary of tasks together with language modelling, studying comprehension, and query answering. Because then, an even bigger product named Megatron-Turing NLG has been printed with 530 billion parameters.
Owing to the sizeable price tag of teaching these substantial versions, it is paramount to estimate the most effective probable coaching set up to avoid squandering means. In certain, the teaching compute value for transformers is determined by two aspects: the model size and the number of training tokens.
The present generation of substantial language styles has allotted greater computational means to raising the parameter count of significant versions and keeping the instruction facts size fastened at all around 300 billion tokens. In this perform, we empirically investigate the ideal tradeoff involving escalating design sizing and the amount of money of education data with escalating computational sources. Specially, we check with the concern: “What is the ideal design dimensions and quantity of instruction tokens for a offered compute spending budget?” To reply this issue, we practice styles of various sizes and with various figures of tokens, and estimate this trade-off empirically.
Our most important finding is that the current big language designs are significantly far too huge for their compute spending budget and are not currently being trained on enough info. In truth, we discover that for the number of coaching FLOPs made use of to train Gopher, a 4x lesser product educated on 4x extra information would have been preferable.
.png)
We check our data scaling speculation by education Chinchilla, a 70-billion parameter product qualified for 1.3 trillion tokens. Although the training compute price for Chinchilla and Gopher are the similar, we come across that it outperforms Gopher and other massive language types on almost just about every calculated process, inspite of getting 70 billion parameters when compared to Gopher’s 280 billion.

After the release of Chinchilla, a model named PaLM was released with 540 billion parameters and skilled on 768 billion tokens. This model was skilled with roughly 5x the compute price range of Chinchilla and outperformed Chinchilla on a assortment of jobs. Though the schooling corpus is distinct, our techniques do predict that this kind of a product trained on our details would outperform Chinchilla even with not currently being compute-best. Supplied the PaLM compute budget, we forecast a 140-billion-parameter product educated on 3 trillion tokens to be optimal and extra economical for inference.
An additional advantage of more compact, much more performant models is that the inference time and memory costs are lowered building querying the styles both equally faster and possible on less hardware. In exercise, even though the schooling FLOPs between Gopher and Chinchilla are the very same, the expense of employing Chinchilla is significantly smaller sized, in addition to it doing superior. Even more uncomplicated optimisations may possibly be achievable that are capable to continue on to present substantial gains.
[ad_2]
Resource hyperlink