
[ad_1]
Clustering is a central dilemma in unsupervised machine understanding (ML) with several programs across domains in the two field and tutorial study far more broadly. At its main, clustering is composed of the adhering to difficulty: supplied a established of knowledge components, the goal is to partition the knowledge elements into teams these kinds of that comparable objects are in the identical group, even though dissimilar objects are in distinctive groups. This challenge has been analyzed in math, laptop science, operations investigate and data for a lot more than 60 many years in its myriad variants. Two popular sorts of clustering are metric clustering, in which the aspects are details in a metric place, like in the k-suggests trouble, and graph clustering, in which the things are nodes of a graph whose edges symbolize similarity among the them.
 |
| In the k-indicates clustering difficulty, we are supplied a established of factors in a metric space with the aim to recognize k agent points, identified as facilities (listed here depicted as triangles), so as to minimize the sum of the squared distances from just about every point to its closest heart. Source, legal rights: CC-BY-SA-4. |
Regardless of the in depth literature on algorithm design and style for clustering, few simple functions have focused on rigorously safeguarding the user’s privacy during clustering. When clustering is utilized to private details (e.g., the queries a consumer has designed), it is needed to take into account the privacy implications of utilizing a clustering resolution in a real method and how significantly data the output resolution reveals about the input info.
To guarantee privateness in a arduous perception, 1 remedy is to acquire differentially private (DP) clustering algorithms. These algorithms make sure that the output of the clustering does not expose non-public data about a certain knowledge ingredient (e.g., no matter whether a consumer has made a specified question) or sensitive details about the enter graph (e.g., a partnership in a social network). Provided the great importance of privacy protections in unsupervised equipment mastering, in new years Google has invested in exploration on idea and practice of differentially non-public metric or graph clustering, and differential privateness in a range of contexts, e.g., heatmaps or instruments to structure DP algorithms.
These days we are enthusiastic to announce two crucial updates: 1) a new differentially-private algorithm for hierarchical graph clustering, which we’ll be presenting at ICML 2023, and 2) the open up-source release of the code of a scalable differentially-personal k-implies algorithm. This code brings differentially personal k-implies clustering to substantial scale datasets utilizing distributed computing. Here, we will also discuss our get the job done on clustering technological know-how for a new start in the health area for informing public well being authorities.
Differentially private hierarchical clustering
Hierarchical clustering is a well known clustering method that is made up of recursively partitioning a dataset into clusters at an progressively finer granularity. A well regarded case in point of hierarchical clustering is the phylogenetic tree in biology in which all existence on Earth is partitioned into finer and finer teams (e.g., kingdom, phylum, class, purchase, and so forth.). A hierarchical clustering algorithm gets as enter a graph representing the similarity of entities and learns this kind of recursive partitions in an unsupervised way. But at the time of our study no algorithm was acknowledged to compute hierarchical clustering of a graph with edge privacy, i.e., preserving the privacy of the vertex interactions.
In “Differentially-Personal Hierarchical Clustering with Provable Approximation Ensures”, we consider how effectively the dilemma can be approximated in a DP context and set up firm upper and reduced bounds on the privateness assure. We style and design an approximation algorithm (the to start with of its variety) with a polynomial managing time that achieves both equally an additive mistake that scales with the variety of nodes n (of get n2.5) and a multiplicative approximation of O(log½ n), with the multiplicative mistake identical to the non-private setting. We further present a new decreased sure on the additive error (of order n2) for any personal algorithm (irrespective of its jogging time) and present an exponential-time algorithm that matches this reduced bound. Furthermore, our paper involves a past-worst-case examination focusing on the hierarchical stochastic block product, a conventional random graph product that exhibits a pure hierarchical clustering construction, and introduces a private algorithm that returns a alternative with an additive value above the the best possible that is negligible for much larger and larger sized graphs, all over again matching the non-non-public condition-of-the-art strategies. We believe that this operate expands the comprehending of privacy preserving algorithms on graph information and will enable new applications in such settings.
Big-scale differentially private clustering
We now swap gears and discuss our work for metric house clustering. Most prior get the job done in DP metric clustering has concentrated on increasing the approximation ensures of the algorithms on the k-implies goal, leaving scalability questions out of the image. Without a doubt, it is not very clear how productive non-personal algorithms these kinds of as k-suggests++ or k-means// can be manufactured differentially non-public with out sacrificing greatly possibly on the approximation guarantees or the scalability. On the other hand, equally scalability and privateness are of key great importance at Google. For this cause, we not too long ago posted several papers that tackle the trouble of developing economical differentially private algorithms for clustering that can scale to large datasets. Our goal is, in addition, to supply scalability to massive scale enter datasets, even when the target quantity of facilities, k, is substantial.
We perform in the massively parallel computation (MPC) product, which is a computation design representative of contemporary dispersed computation architectures. The model is composed of a number of equipment, just about every keeping only aspect of the enter facts, that work together with the intention of resolving a international challenge while minimizing the total of communication between equipment. We current a differentially private continuous element approximation algorithm for k-suggests that only needs a regular range of rounds of synchronization. Our algorithm builds on our past work on the difficulty (with code out there in this article), which was the initial differentially-non-public clustering algorithm with provable approximation ensures that can do the job in the MPC product.
The DP frequent factor approximation algorithm dramatically improves on the former work applying a two period tactic. In an original stage it computes a crude approximation to “seed” the second phase, which is made up of a much more complex distributed algorithm. Outfitted with the 1st-step approximation, the second section relies on final results from the Coreset literature to subsample a applicable established of enter points and discover a superior differentially non-public clustering alternative for the enter points. We then demonstrate that this option generalizes with approximately the same warranty to the full enter.
Vaccination lookup insights by means of DP clustering
We then utilize these advances in differentially non-public clustering to actual-planet apps. A person example is our software of our differentially-non-public clustering alternative for publishing COVID vaccine-relevant queries, whilst supplying robust privateness protections for the people.
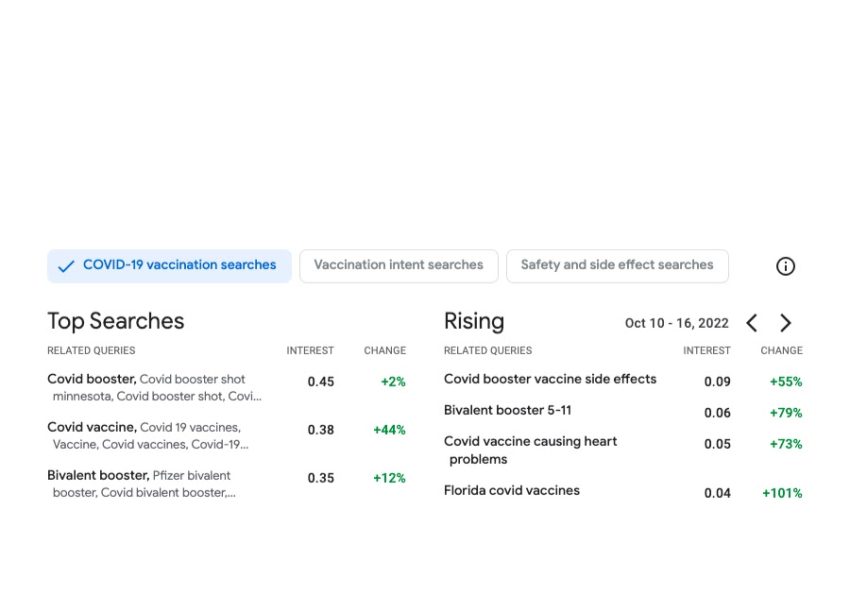
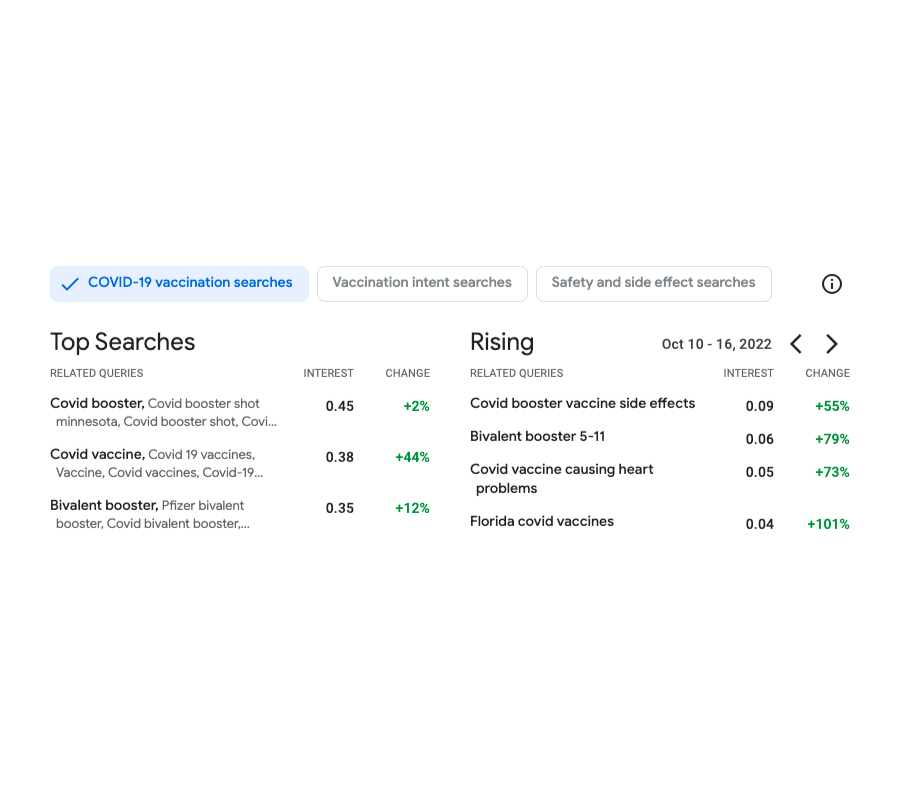
The objective of Vaccination Research Insights (VSI) is to help public wellness selection makers (overall health authorities, government businesses and nonprofits) recognize and answer to communities’ data wants regarding COVID vaccines. In buy to achieve this, the software permits users to examine at distinctive geolocation granularities (zip-code, county and condition degree in the U.S.) the best themes searched by consumers relating to COVID queries. In distinct, the device visualizes data on trending queries increasing in interest in a provided locale and time.
 |
| Screenshot of the output of the software. Exhibited on the still left, the major lookups connected to Covid vaccines for the duration of the time period Oct 10-16 2022. On the ideal, the queries that have experienced increasing worth during the exact time period and when compared to the former 7 days. |
To far better aid identifying the themes of the trending searches, the instrument clusters the research queries dependent on their semantic similarity. This is done by making use of a custom made-developed k-means–based algorithm run in excess of search info that has been anonymized employing the DP Gaussian mechanism to incorporate noise and take out small-count queries (hence resulting in a differentially clustering). The system ensures powerful differential privateness ensures for the defense of the person information.
This instrument offered fantastic-grained data on COVID vaccine perception in the populace at unparalleled scales of granularity, one thing that is primarily appropriate to comprehend the requirements of the marginalized communities disproportionately influenced by COVID. This undertaking highlights the influence of our financial investment in investigation in differential privateness, and unsupervised ML methods. We are wanting to other significant parts wherever we can implement these clustering techniques to aid guidebook selection building all around world wide health and fitness issues, like research queries on local weather change–related problems these types of as air high quality or intense warmth.
Acknowledgements
We thank our co-authors Jacob Imola, Silvio Lattanzi, Mohammad Mahdian, Vahab Mirrokni, Andres Munoz Medina, Shyam Narayanan, David Saulpic, Chris Schwiegelshohn, Sergei Vassilvitskii, Peilin Zhong, and our colleagues from the Well being AI team that designed the VSI launch feasible, Shailesh Bavadekar, Adam Boulanger, Tague Griffith, Mansi Kansal, Chaitanya Kamath, Akim Kumok, Yael Mayer, Tomer Shekel, Megan Shum, Charlotte Stanton, Mimi Solar, Swapnil Vispute, and Mark Youthful.
For extra data on the Graph Mining staff (section of Algorithm and Optimization) go to our pages.
[ad_2]
Resource connection