

[ad_1]

Picture from Creator | Bing Image Creator
Dolly 2. is an open up-resource, instruction-adopted, big language model (LLM) that was great-tuned on a human-created dataset. It can be made use of for both equally investigate and commercial functions.
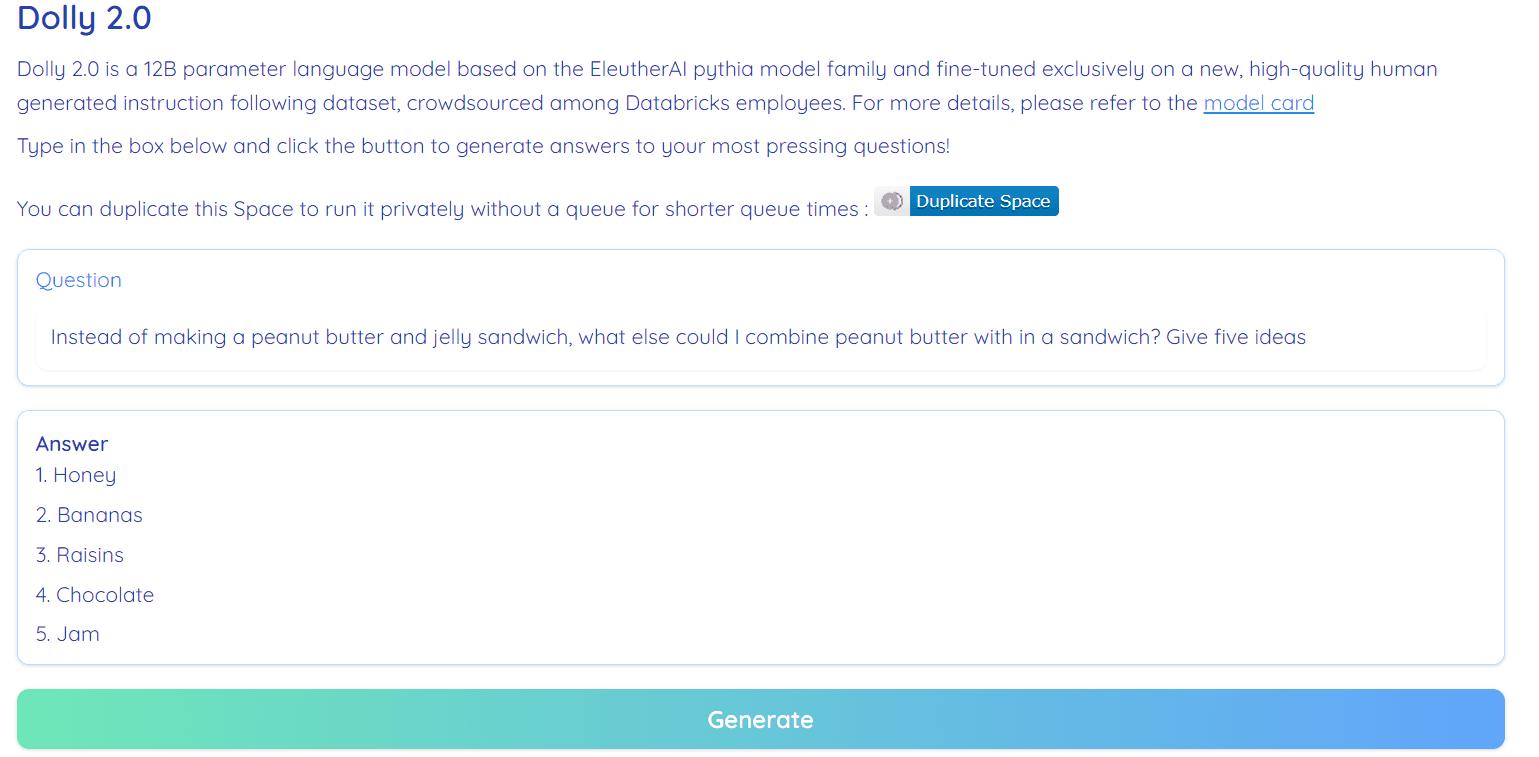
Impression from Hugging Confront Place by RamAnanth1
Beforehand, the Databricks workforce launched Dolly 1., LLM, which exhibits ChatGPT-like instruction subsequent capability and costs a lot less than $30 to train. It was employing the Stanford Alpaca workforce dataset, which was underneath a limited license (Investigate only).
Dolly 2. has resolved this problem by good-tuning the 12B parameter language model (Pythia) on a superior-good quality human-generated instruction in the following dataset, which was labeled by a Datbricks employee. Equally product and dataset are readily available for professional use.
Dolly 1. was skilled on a Stanford Alpaca dataset, which was created using OpenAI API. The dataset has the output from ChatGPT and stops any one from making use of it to compete with OpenAI. In quick, you can’t develop a commercial chatbot or language application based on this dataset.
Most of the hottest types unveiled in the last handful of weeks endured from the identical problems, types like Alpaca, Koala, GPT4All, and Vicuna. To get around, we need to have to develop new high-high quality datasets that can be utilised for professional use, and that is what the Databricks workforce has finished with the databricks-dolly-15k dataset.
The new dataset consists of 15,000 high-top quality human-labeled prompt/reaction pairs that can be made use of to style instruction tuning massive language versions. The databricks-dolly-15k dataset arrives with Imaginative Commons Attribution-ShareAlike 3. Unported License, which permits any one to use it, modify it, and generate a business software on it.
How did they develop the databricks-dolly-15k dataset?
The OpenAI analysis paper states that the initial InstructGPT design was properly trained on 13,000 prompts and responses. By applying this info, the Databricks group begun to get the job done on it, and it turns out that creating 13k inquiries and solutions was a hard task. They can not use artificial info or AI generative info, and they have to deliver primary answers to every issue. This is the place they have determined to use 5,000 staff members of Databricks to make human-produced details.
The Databricks have established up a contest, in which the top rated 20 labelers would get a significant award. In this contest, 5,000 Databricks employees participated that had been pretty intrigued in LLMs
The dolly-v2-12b is not a point out-of-the-artwork design. It underperforms dolly-v1-6b in some evaluation benchmarks. It could possibly be owing to the composition and dimensions of the underlying great-tuning datasets. The Dolly design loved ones is underneath lively advancement, so you may possibly see an up to date variation with superior overall performance in the long run.
In quick, the dolly-v2-12b model has performed better than EleutherAI/gpt-neox-20b and EleutherAI/pythia-6.9b.

Image from Free Dolly
Dolly 2. is 100% open up-resource. It arrives with teaching code, dataset, product weights, and inference pipeline. All of the elements are ideal for business use. You can consider out the model on Hugging Experience Spaces Dolly V2 by RamAnanth1.
Graphic from Hugging Confront
Resource:
Dolly 2. Demo: Dolly V2 by RamAnanth1
Abid Ali Awan (@1abidaliawan) is a qualified details scientist expert who loves creating machine studying products. Presently, he is focusing on articles creation and crafting specialized weblogs on machine finding out and facts science technologies. Abid holds a Master’s degree in Technological know-how Management and a bachelor’s diploma in Telecommunication Engineering. His eyesight is to build an AI products employing a graph neural network for pupils battling with psychological disease.
[ad_2]
Source link