
[ad_1]
It is no top secret that OpenAI’s ChatGPT has some incredible capabilities — for instance, the chatbot can publish poetry that resembles Shakespearean sonnets or debug code for a computer system program. These capabilities are made attainable by the massive machine-discovering model that ChatGPT is crafted on. Scientists have identified that when these sorts of models grow to be significant plenty of, extraordinary capabilities emerge.
But even larger models also call for far more time and funds to train. The teaching system will involve exhibiting hundreds of billions of examples to a design. Gathering so a great deal facts is an associated method in by itself. Then arrive the monetary and environmental prices of jogging several powerful desktops for days or months to teach a model that may have billions of parameters.
“It’s been estimated that education versions at the scale of what ChatGPT is hypothesized to run on could get tens of millions of pounds, just for a one education run. Can we increase the effectiveness of these schooling approaches, so we can nonetheless get very good styles in much less time and for a lot less income? We suggest to do this by leveraging more compact language versions that have earlier been properly trained,” says Yoon Kim, an assistant professor in MIT’s Division of Electrical Engineering and Pc Science and a member of the Personal computer Science and Synthetic Intelligence Laboratory (CSAIL).
Somewhat than discarding a former version of a design, Kim and his collaborators use it as the creating blocks for a new product. Applying machine mastering, their approach learns to “grow” a more substantial product from a lesser model in a way that encodes understanding the smaller sized design has previously attained. This enables more rapidly schooling of the greater model.
Their strategy saves about 50 p.c of the computational charge needed to coach a significant design, as opposed to strategies that teach a new product from scratch. Plus, the models trained applying the MIT approach executed as very well as, or far better than, types experienced with other tactics that also use more compact designs to enable more rapidly education of greater designs.
Lowering the time it can take to practice substantial types could help researchers make advancements more quickly with fewer cost, when also reducing the carbon emissions generated through the coaching method. It could also permit smaller analysis teams to get the job done with these significant models, potentially opening the doorway to numerous new improvements.
“As we glimpse to democratize these forms of technologies, generating schooling more rapidly and considerably less pricey will grow to be far more vital,” says Kim, senior author of a paper on this approach.
Kim and his graduate scholar Lucas Torroba Hennigen wrote the paper with guide writer Peihao Wang, a graduate college student at the College of Texas at Austin, as very well as other folks at the MIT-IBM Watson AI Lab and Columbia College. The study will be offered at the Intercontinental Conference on Learning Representations.
The bigger the much better
Huge language designs like GPT-3, which is at the main of ChatGPT, are constructed using a neural network architecture identified as a transformer. A neural network, loosely primarily based on the human mind, is composed of levels of interconnected nodes, or “neurons.” Every single neuron includes parameters, which are variables learned during the teaching process that the neuron takes advantage of to course of action details.
Transformer architectures are unique due to the fact, as these varieties of neural community designs get bigger, they obtain considerably much better final results.
“This has led to an arms race of organizations attempting to teach greater and larger sized transformers on more substantial and larger datasets. A lot more so than other architectures, it appears to be that transformer networks get much superior with scaling. We’re just not accurately positive why this is the scenario,” Kim says.
These models often have hundreds of tens of millions or billions of learnable parameters. Instruction all these parameters from scratch is high priced, so researchers seek to speed up the course of action.
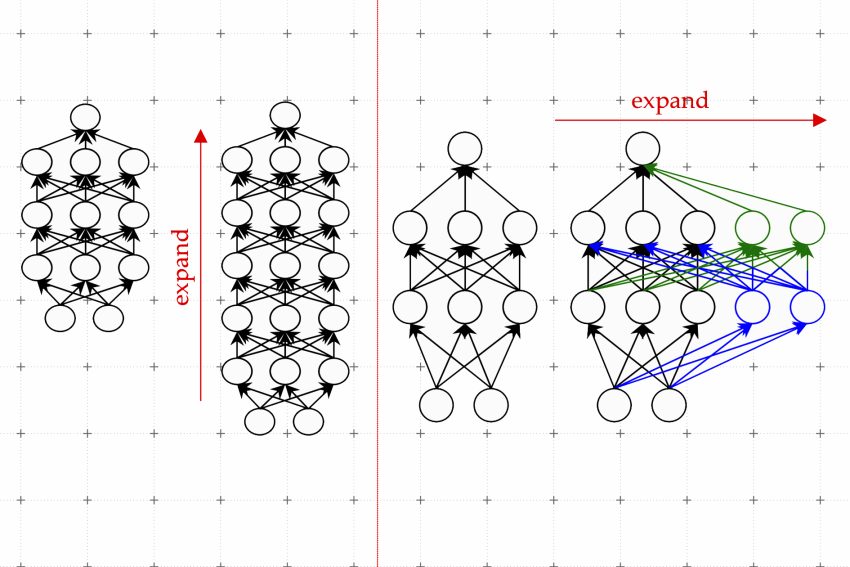
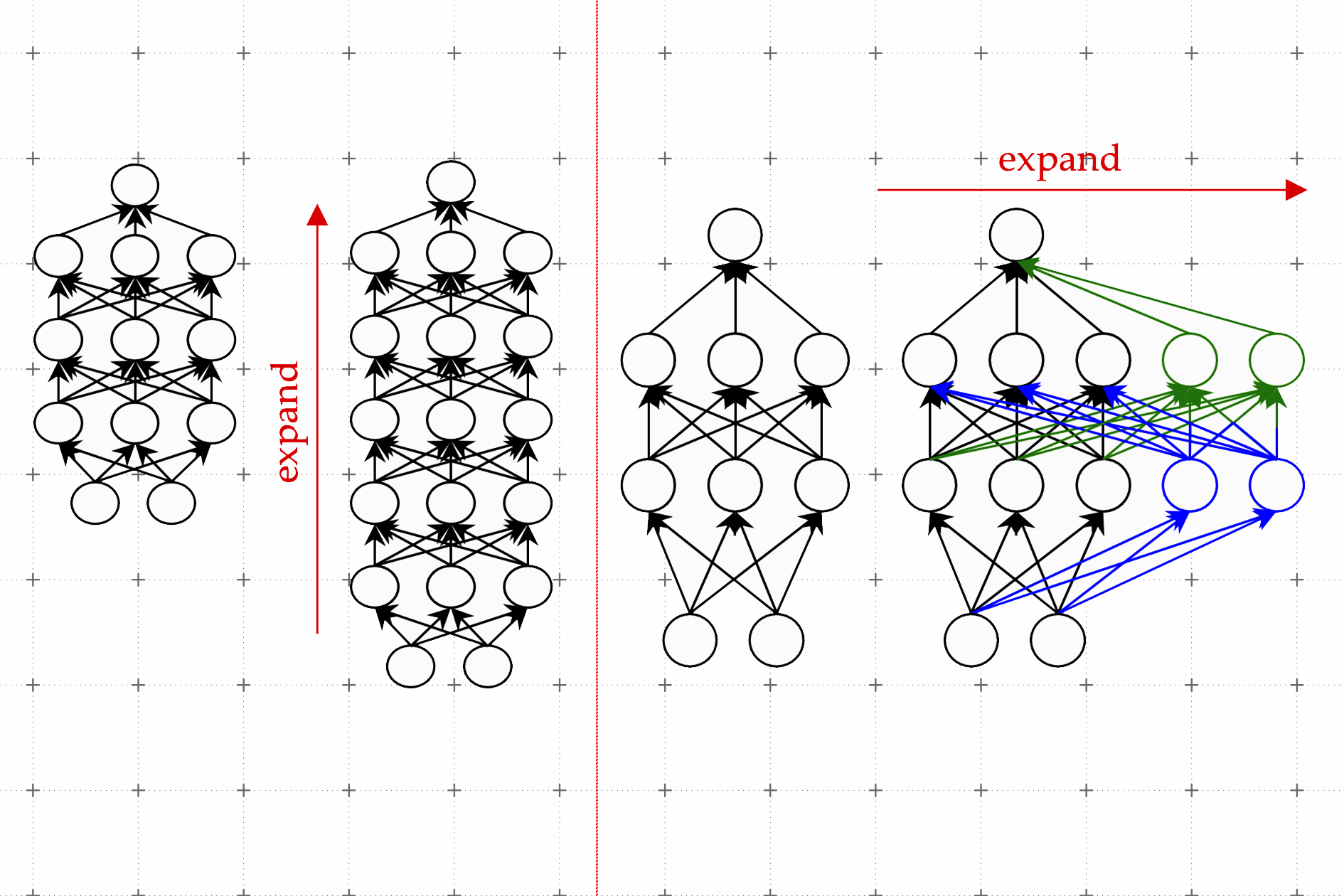
One efficient procedure is acknowledged as model advancement. Employing the design development process, scientists can improve the sizing of a transformer by copying neurons, or even overall layers of a prior edition of the community, then stacking them on top. They can make a network wider by introducing new neurons to a layer or make it further by incorporating further layers of neurons.
In contrast to prior strategies for model advancement, parameters related with the new neurons in the expanded transformer are not just copies of the scaled-down network’s parameters, Kim clarifies. Somewhat, they are uncovered mixtures of the parameters of the smaller sized model.
Mastering to increase
Kim and his collaborators use equipment mastering to study a linear mapping of the parameters of the more compact product. This linear map is a mathematical procedure that transforms a set of input values, in this circumstance the lesser model’s parameters, to a set of output values, in this situation the parameters of the more substantial design.
Their strategy, which they simply call a discovered Linear Progress Operator (LiGO), learns to grow the width and depth of bigger community from the parameters of a smaller sized network in a details-pushed way.
But the lesser model might really be quite substantial — possibly it has a hundred million parameters — and researchers may possibly want to make a model with a billion parameters. So the LiGO strategy breaks the linear map into more compact parts that a device-understanding algorithm can handle.
LiGO also expands width and depth simultaneously, which will make it far more successful than other methods. A consumer can tune how large and deep they want the more substantial product to be when they enter the smaller product and its parameters, Kim clarifies.
When they in comparison their strategy to the method of teaching a new product from scratch, as perfectly as to product-expansion strategies, it was more quickly than all the baselines. Their method saves about 50 % of the computational fees required to educate both eyesight and language designs, even though usually enhancing overall performance.
The researchers also located they could use LiGO to speed up transformer instruction even when they did not have accessibility to a lesser, pretrained product.
“I was shocked by how significantly improved all the procedures, which includes ours, did compared to the random initialization, educate-from-scratch baselines.” Kim claims.
In the future, Kim and his collaborators are looking ahead to implementing LiGO to even bigger designs.
The work was funded, in part, by the MIT-IBM Watson AI Lab, Amazon, the IBM Exploration AI Components Heart, Centre for Computational Innovation at Rensselaer Polytechnic Institute, and the U.S. Army Exploration Business.
[ad_2]
Supply hyperlink