
[ad_1]
The synthesis of new sights is a warm topic in laptop graphics and vision purposes, this kind of as digital and augmented actuality, immersive pictures, and the progress of digital replicas. The objective is to generate further views of an object or a scene based on limited first viewpoints. This job is especially demanding mainly because the recently synthesized sights have to think about occluded regions and formerly unseen regions.
Just lately, neural radiance fields (NeRF) have demonstrated excellent final results in creating higher-good quality novel sights. On the other hand, NeRF depends on a major quantity of visuals, ranging from tens to hundreds, to efficiently capture the scene, making it susceptible to overfitting and lacking the capacity to generalize to new scenes.
Prior makes an attempt have launched generalizable NeRF styles that condition the NeRF illustration dependent on the projection of 3D factors and extracted impression functions. These ways generate satisfactory effects, specially for sights close to the enter picture. Nevertheless, when the focus on sights noticeably differ from the enter, these procedures deliver blurry outcomes. The challenge lies in resolving the uncertainty involved with big unseen areas in the novel views.
An alternate tactic to tackle the uncertainty problem in single-picture perspective synthesis consists of employing 2D generative designs that predict novel views when conditioning on the input see. Even so, the hazard for these methods is the lack of consistency in picture era with the underlying 3D construction.
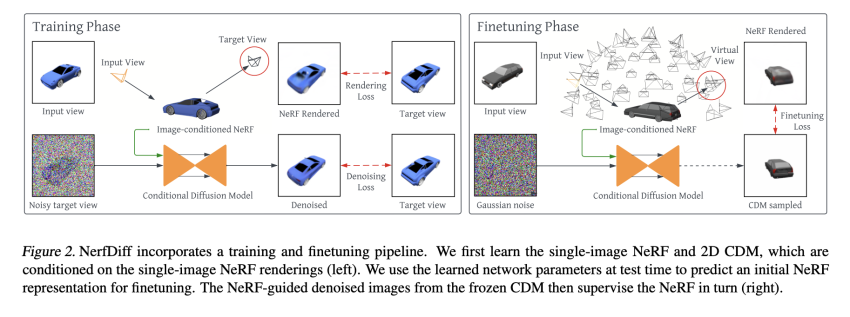
For this goal, a new method known as NerfDiff has been offered. NerfDiff is a framework built for synthesizing substantial-good quality multi-view dependable illustrations or photos based mostly on one-look at input. An overview of the workflow is offered in the determine below.

The proposed approach is composed of two stages: teaching and finetuning.
For the duration of the teaching phase, a digital camera-space triplane-based mostly NeRF model and a 3D-conscious conditional diffusion product (CDM) are jointly trained on a selection of scenes. The NeRF illustration is initialized working with the enter picture at the finetuning stage. Then, the parameters of the NeRF product are modified centered on a set of virtual illustrations or photos generated by the CDM, which is conditioned on the NeRF-rendered outputs. Nonetheless, a clear-cut finetuning tactic that optimizes the NeRF parameters directly making use of the CDM outputs provides very low-good quality renderings thanks to the multi-view inconsistency of the CDM outputs. To handle this issue, the researchers propose NeRF-guided distillation, an alternating approach that updates the NeRF illustration and guides the multi-view diffusion method. Exclusively, this approach enables the resolution of uncertainty in solitary-impression look at synthesis by leveraging the more facts provided by the CDM. Simultaneously, the NeRF design guides the CDM to make certain multi-look at consistency during the diffusion approach.
Some of the final results received by means of NerfDiff are described in this article beneath (where NGD stands for Nerf-Guided Distillation).

This was the summary of NerfDiff, a novel AI framework to permit high-high-quality and regular many views from a one input graphic. If you are intrigued, you can learn additional about this strategy in the one-way links below.
Check out out the Paper and Venture. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Electronic mail Newsletter, the place we share the latest AI investigation news, awesome AI initiatives, and much more. If you have any queries concerning the over post or if we missed everything, experience no cost to e mail us at [email protected]
🚀 Check Out 100’s AI Resources in AI Applications Club
Daniele Lorenzi received his M.Sc. in ICT for Online and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. prospect at the Institute of Details Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is at present doing work in the Christian Doppler Laboratory ATHENA and his investigate pursuits incorporate adaptive movie streaming, immersive media, equipment learning, and QoS/QoE evaluation.
[ad_2]
Supply backlink