
[ad_1]
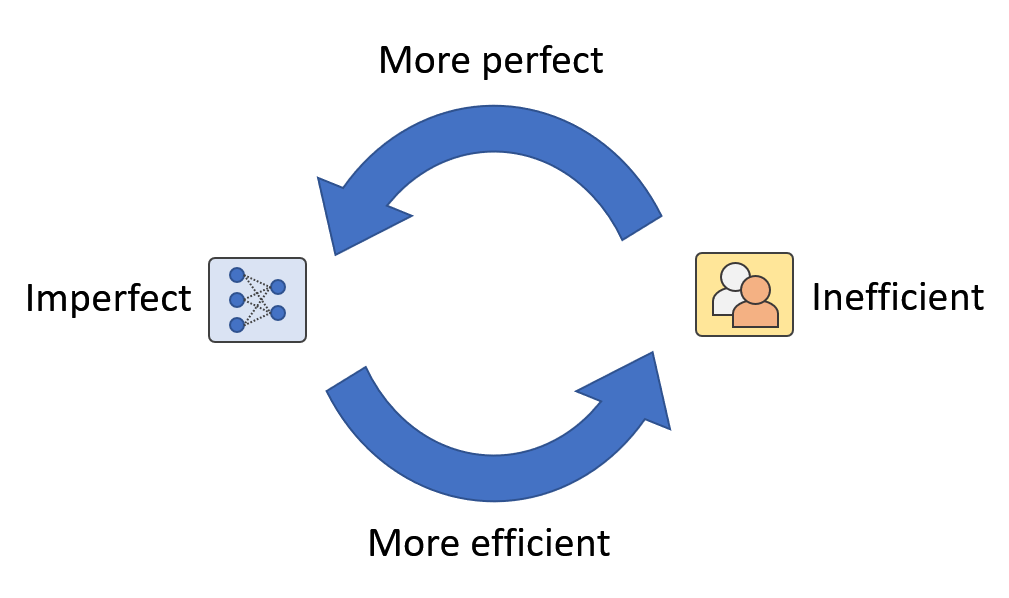
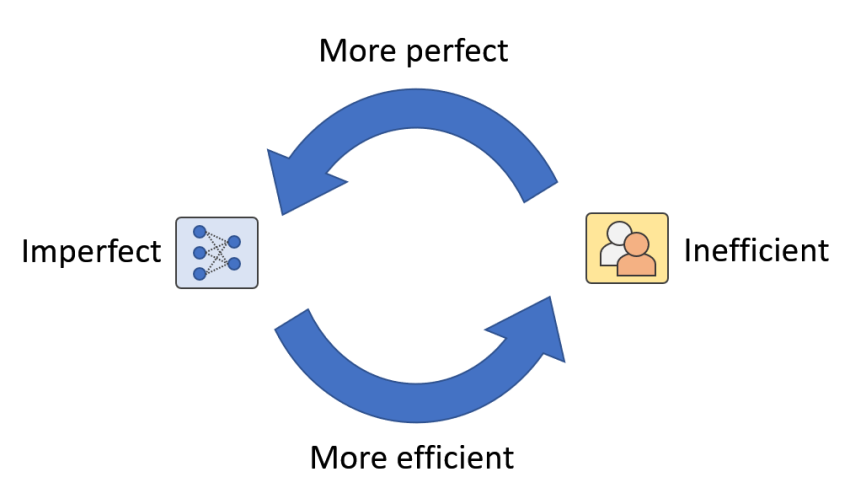
Figure 1: In authentic-environment purposes, we feel there exist a human-equipment loop the place human beings and equipment are mutually augmenting each individual other. We get in touch with it Artificial Augmented Intelligence.
How do we make and consider an AI technique for authentic-entire world programs? In most AI analysis, the analysis of AI methods entails a instruction-validation-tests course of action. The experiments generally stop when the versions have excellent tests overall performance on the claimed datasets because authentic-planet details distribution is assumed to be modeled by the validation and tests information. Having said that, authentic-entire world apps are usually much more sophisticated than a solitary teaching-validation-tests course of action. The most important change is the at any time-altering facts. For instance, wildlife datasets transform in course composition all the time since of animal invasion, re-introduction, re-colonization, and seasonal animal movements. A model qualified, validated, and examined on present datasets can very easily be damaged when newly gathered knowledge comprise novel species. The good thing is, we have out-of-distribution detection methods that can aid us detect samples of novel species. However, when we want to broaden the recognition capacity (i.e., being equipped to figure out novel species in the upcoming), the very best we can do is wonderful-tuning the models with new ground-truthed annotations. In other words and phrases, we need to include human effort/annotations irrespective of how the products execute on former testing sets.
When human annotations are unavoidable, true-earth recognition devices turn into a never ever-ending loop of data assortment → annotation → model wonderful-tuning (Figure 2). As a final result, the general performance of a person one phase of model analysis does not represent the precise generalization of the total recognition method simply because the design will be up to date with new facts annotations, and a new spherical of evaluation will be executed. With this loop in head, we think that as a substitute of constructing a product with greater tests functionality, focusing on how substantially human energy can be saved is a far more generalized and sensible aim in serious-earth programs.
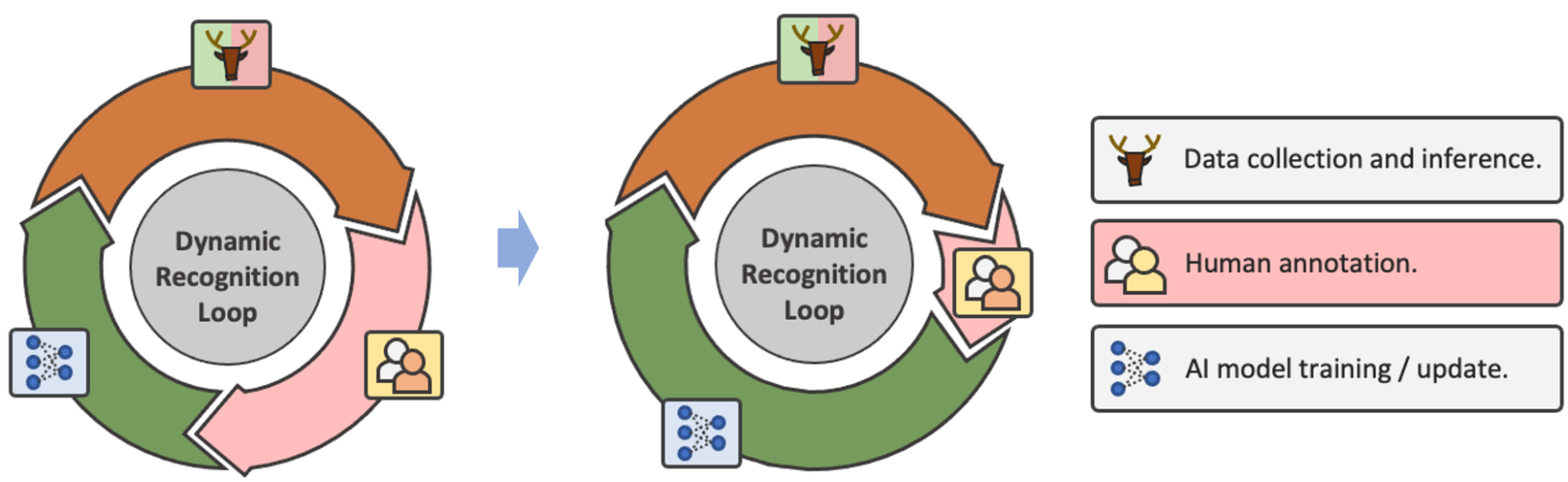
Determine 2: In the loop of information selection, annotation, and model update, the purpose of optimization gets to be minimizing the requirement of human annotation relatively than solitary-stage recognition functionality.
In the paper we posted past year in Mother nature-Machine Intelligence [1], we talked over the incorporation of human-in-the-loop into wildlife recognition and proposed to examine human effort performance in model updates instead of basic tests effectiveness. For demonstration, we developed a recognition framework that was a mix of energetic mastering, semi-supervised mastering, and human-in-the-loop (Determine 3). We also incorporated a time element into this framework to suggest that the recognition types did not stop at any single time stage. Typically speaking, in the framework, at every time action, when new info are collected, a recognition product actively selects which details really should be annotated centered on a prediction self-confidence metric. Very low-assurance predictions are despatched for human annotation, and high-self confidence predictions are dependable for downstream tasks or pseudo-labels for design updates.
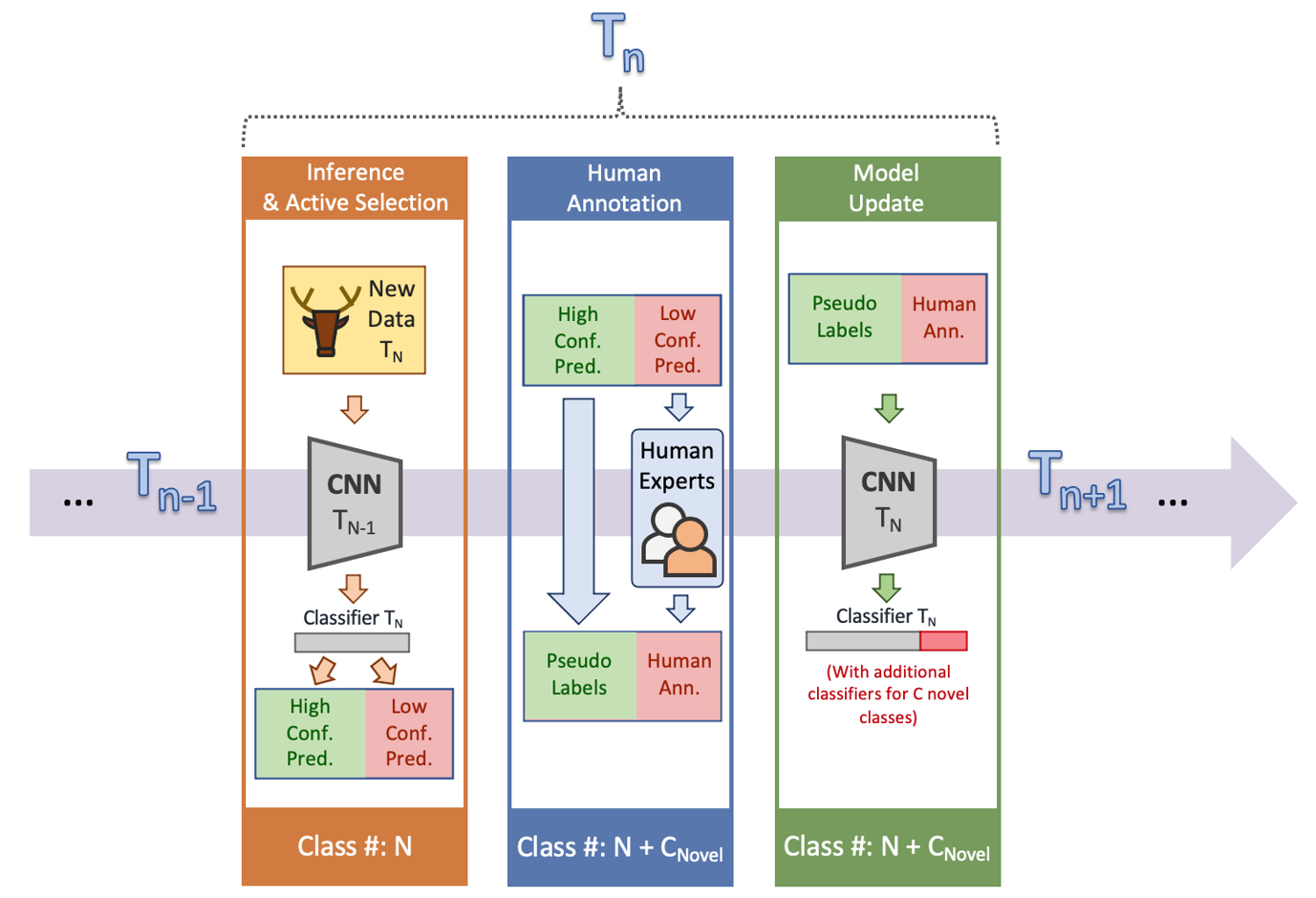
Determine 3: Right here, we current an iterative recognition framework that can both optimize the utility of modern day impression recognition procedures and limit the dependence on guide annotations for product updating.
In phrases of human annotation performance for product updates, we split the evaluation into 1) the share of substantial-self confidence predictions on validation (i.e., saved human work for annotation) 2) the accuracy of higher-self-confidence predictions (i.e., dependability) and 3) the percentage of novel classes that are detected as low-self-confidence predictions (i.e., sensitivity to novelty). With these 3 metrics, the optimization of the framework turns into reducing human endeavours (i.e., to improve superior-self-confidence proportion) and maximizing product update functionality and substantial-self esteem accuracy.
We reported a two-action experiment on a massive-scale wildlife digital camera lure dataset collected from Mozambique National Park for demonstration functions. The initially action was an initialization step to initialize a design with only aspect of the dataset. In the second phase, a new established of data with recognized and novel courses was used to the initialized product. Pursuing the framework, the design manufactured predictions on the new dataset with self confidence, in which large-self esteem predictions were trusted as pseudo-labels, and reduced-assurance predictions were being delivered with human annotations. Then, the product was current with both pseudo-labels and annotations and prepared for the long run time steps. As a result, the percentage of high-self-confidence predictions on 2nd step validation was 72.2%, the accuracy of significant-self esteem predictions was 90.2%, and the proportion of novel lessons detected as small-self-confidence was 82.6%. In other terms, our framework saved 72% of human work on annotating all the next move facts. As long as the product was confident, 90% of the predictions had been right. In addition, 82% of novel samples have been productively detected. Details of the framework and experiments can be located in the first paper.
By having a closer appear at Figure 3, other than the data selection – human annotation – product update loop, there is a different human-equipment loop concealed in the framework (Determine 1). This is a loop in which equally humans and equipment are continuously increasing each individual other via design updates and human intervention. For case in point, when AI designs are not able to recognize novel classes, human intervention can supply information and facts to increase the model’s recognition capacity. On the other hand, when AI products get additional and much more generalized, the prerequisite for human hard work receives less. In other text, the use of human work gets additional efficient.
In addition, the self esteem-based mostly human-in-the-loop framework we proposed is not minimal to novel course detection but can also assistance with challenges like long-tailed distribution and multi-area discrepancies. As prolonged as AI versions sense a lot less self-confident, human intervention will come in to enable boost the design. Likewise, human effort and hard work is saved as extensive as AI designs come to feel self-confident, and at times human problems can even be corrected (Figure 4). In this case, the partnership involving humans and devices turns into synergistic. As a result, the aim of AI advancement variations from changing human intelligence to mutually augmenting both human and equipment intelligence. We get in touch with this kind of AI: Synthetic Augmented Intelligence (A2I).
Ever since we began operating on synthetic intelligence, we have been asking ourselves, what do we make AI for? At first, we thought that, preferably, AI need to thoroughly substitute human hard work in basic and laborous responsibilities these as significant-scale impression recognition and car driving. As a result, we have been pushing our styles to an strategy termed “human-amount performance” for a very long time. Nevertheless, this purpose of changing human energy is intrinsically constructing up opposition or a mutually exceptional marriage amongst human beings and machines. In authentic-entire world apps, the performance of AI methods is just minimal by so several influencing components like prolonged-tailed distribution, multi-domain discrepancies, label noise, weak supervision, out-of-distribution detection, etcetera. Most of these issues can be someway relieved with good human intervention. The framework we proposed is just one particular illustration of how these separate complications can be summarized into significant- as opposed to low-self-confidence prediction troubles and how human effort and hard work can be launched into the entire AI method. We think it is not dishonest or surrendering to hard complications. It is a additional human-centric way of AI improvement, the place the target is on how a great deal human hard work is saved somewhat than how several screening images a design can figure out. Prior to the realization of Artificial Basic Intelligence (AGI), we think it is worthwhile to even further examine the path of equipment-human interactions and A2I these types of that AI can start off making more impacts in a variety of simple fields.

Determine 4: Illustrations of superior-confidence predictions that did not match the original annotations. Quite a few high-confidence predictions that were being flagged as incorrect centered on validation labels (offered by pupils and citizen researchers) ended up in reality suitable on nearer inspection by wildlife professionals.
Acknowledgements: We thank all co-authors of the paper “Iterative Human and Automated Identification of Wildlife Images” for their contributions and discussions in making ready this blog. The sights and thoughts expressed in this site are exclusively of the authors of this paper.
This blog publish is primarily based on the next paper which is revealed at Character – Machine Intelligence:
[1] Miao, Zhongqi, Ziwei Liu, Kaitlyn M. Gaynor, Meredith S. Palmer, Stella X. Yu, and Wayne M. Getz. “Iterative human and automated identification of wildlife images.” Mother nature Device Intelligence 3, no. 10 (2021): 885-895.(Backlink to Pre-print)
[ad_2]
Supply link