
[ad_1]
The arduous task of recovering 3D from 2D photos has highly developed swiftly in current yrs, many thanks to neural area-dependent algorithms that allow significant-fidelity 3D recording of regular objects and environments and dense multiview observations. In addition, there has been an upsurge in curiosity in producing it feasible to execute comparable reconstructions in sparse-see configurations when there are only a several pictures of the fundamental instance, these as on the internet marketplaces or everyday consumer grabs. Many sparse-perspective reconstruction approaches have yielded promising outcomes, but they typically rely on identified (specific or approximative) 6D digital camera places for this 3D inference and sidestep the difficulty of how these 6D poses may well be acquired in the initially area.
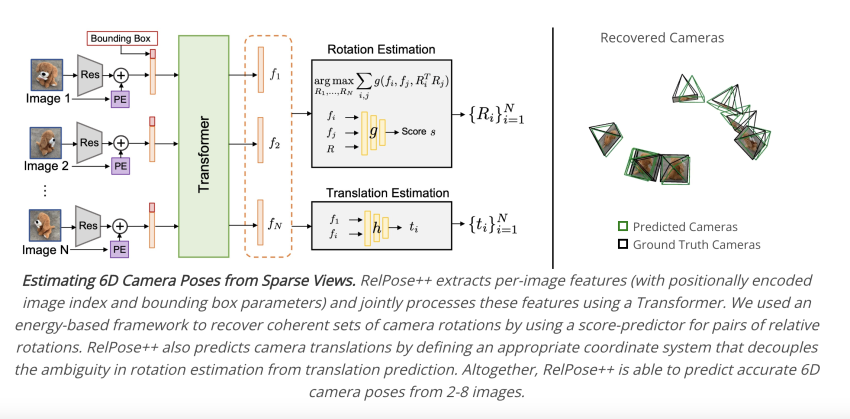
In this analyze, researchers from Carnegie Mellon University produce a program that can fill in this hole and reliably determine (coarse) 6D postures for a generic item, this kind of as a Fetch robotic, from a limited established of shots (Fig. 1). Whilst it is dependent on base-up correspondences, the classic process of recapturing camera postures from a series of photographs is not trustworthy in sparse-check out situations with minor overlap concerning subsequent sights. Alternatively, their function uses a top rated-down strategy and expands on RelPose, which forecasts distributions throughout pairwise relative rotations before optimizing multiview regular rotation hypotheses. RelPose’s projected allocations only contemplate pairs of photographs, which can be restrictive even if this optimization aids in enforcing multiview regularity.

Determine 1: Estimating 6D Digicam Poses from Sparse Views. They recommend the RelPose++ framework, which can decide the needed 6D digicam rotations and translations from a sparse set of input pics (best: the cameras are colored from red to magenta, relying on the image index). RelPose++ may use multi-watch cues whilst estimating a chance distribution throughout the relative rotations of the cameras corresponding to any two photographs. They discover that the distribution receives much better when more photographs are included for context (bottom).
For instance, they are unable to ascertain the Y-axis rotation of the bottle in Determine. 1’s very first two pics considering the fact that the second label could be on possibly the side or the back again of the container. On the other hand, if they also think about the 3rd impression, they can instantly see that the very first two photos really should be rotated by about 180 degrees! They extend on this realization in their framework RelPose++, which they offer, and provide a method for collaboratively reasoning throughout a number of photos to forecast pairwise relative distributions. They particularly consist of a transformer-based module that updates the impression-precise attributes afterward used for relative rotation inference employing context throughout all input photos.
In addition to predicting camera rotations, RelPose++ also infers the digicam translation to deliver 6D digital camera poses. Just one important challenge is that the environment coordinate body used to define camera extrinsic can be arbitrarily preferred. Naive remedies to this dilemma, like instantiating the 1st camera as the world origin, guide to predictions of camera translations and (relative) digicam rotations turning into entangled. As an alternative, they deliver a world coordinate frame centered at the stage where the cameras’ optical axes converge for around centre-experiencing photographs. They show how this aids in decoupling the rotational and translational prediction tasks and generates observable empirical strengths.
RelPose++ can get well 6D digicam poses for objects in obvious and unseen categories given just a number of pictures following being skilled on 41 forms from the CO3D dataset. They find that RelPose++ outperforms the most latest reducing-edge sparse-watch approaches by above 25% concerning rotation prediction accuracy. They illustrate the positive aspects of prediction in their suggested coordinate technique and evaluate the entire 6D camera poses by gauging the accuracy of the expected digital camera centers (while getting similarity transform ambiguity into consideration). In the hopes that it may perhaps also be helpful for analyzing upcoming approaches, they also produce a measure that assesses the precision of camera translations (decoupled from the precision of anticipated rotations). Ultimately, they demonstrate how the 6D poses from RelPose++ can straight reward 3D reconstruction approaches that make the most of sparse views in the foreseeable future. The code and demo are manufactured readily available on GitHub.
Check out out the Paper, GitHub connection, and Project web page. Don’t overlook to join our 22k+ ML SubReddit, Discord Channel, and E-mail E-newsletter, where we share the most up-to-date AI analysis information, interesting AI initiatives, and far more. If you have any queries pertaining to the previously mentioned short article or if we skipped anything at all, really feel free of charge to electronic mail us at [email protected]
🚀 Examine Out 100’s AI Applications in AI Resources Club
Aneesh Tickoo is a consulting intern at MarktechPost. He is at present pursuing his undergraduate diploma in Info Science and Synthetic Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time doing work on tasks aimed at harnessing the electricity of machine mastering. His investigation curiosity is impression processing and is passionate about developing answers close to it. He loves to join with folks and collaborate on attention-grabbing tasks.
[ad_2]
Resource url