
[ad_1]
Iterative refinement is a crucial part of human challenge-resolving. Iterative refinement is a procedure that will involve earning an initial draught and then improving upon it as a result of self-comments. For instance, even though producing an e-mail to a coworker to request a document, a individual would initial use a uncomplicated ask for like “give me the facts Quickly.” But, after some assumed, the author could notice that the phrase could be viewed as unfriendly and transformed it to “Could you kindly present me the facts?” Utilizing iterative comments and modification, they show in this analyze that significant language types (LLMs) can properly mimic this cognitive method in individuals.
Though LLMs are capable of producing coherent outputs in the first phase, they regularly tumble small when addressing far more elaborate specifications, especially for jobs with multiple goals (this kind of as dialogue reaction era with standards like creating the response pertinent, participating, and protected) or individuals with considerably less distinct aims (e.g., maximizing program readability). Modern LLMs may perhaps produce understandable output in this sort of conditions. Even now, iterative advancement is expected to guarantee that all assignment necessities are dealt with and that the appropriate amount of high quality is attained.
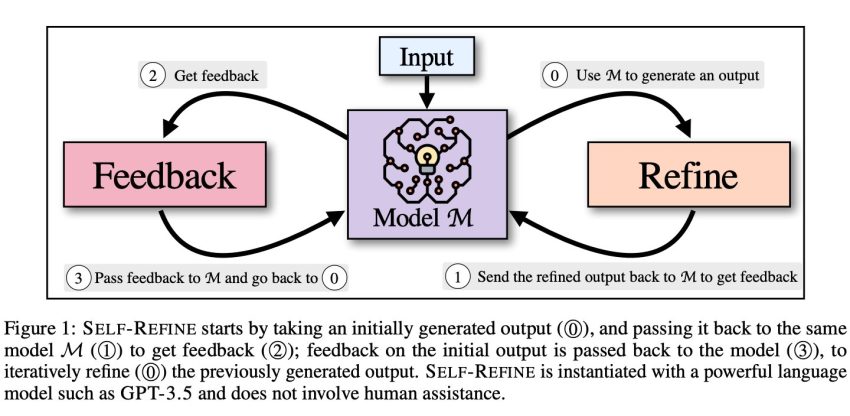
Innovative strategies that count on third-get together reward and supervision designs phone either great amounts of coaching data or highly-priced human annotations, which are normally practical to get. These negatives spotlight the require for a extra adaptable and economical process of text era that may be used for lots of careers with minimal monitoring. In this examine, scientists from CMU, Allen Institute, University of Washington, NVIDIA, UCSD, and Google Study, propose SELF-REFINE prevail over these constraints and improved replicate the human resourceful creation process without a high priced human feedback loop. (Determine 1).
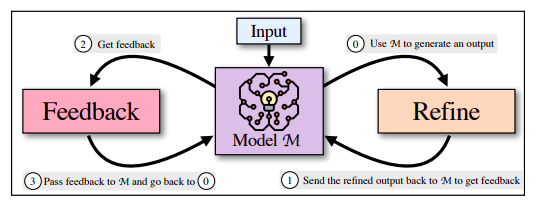
The two halves of SELF-REFINE—FEEDBACK and REFINE—work with each other in an iterative cycle to produce higher-quality final results. They transmit the identical product M (1), an first draught output generated by product M (), to get responses (1). The exact model (3) is given feed-back on the initial generation, which iteratively improves () the output that was originally produced. Iteratively repeating this treatment continues until finally the model deems no additional advancement is essential, at which position the procedure ends. The central thesis of this study is that in a several-shot situation, the very same fundamental language model handles feed-back and refining.
SELF-REFINE supplies the first iterative tactic to enrich era utilizing NL feedback effectively.
Figure 1 depicts the course of action in an illustration. They use SELF-REFINE to full numerous responsibilities that span several domains and contact for opinions and revision tactics, these as assessment rewriting, acronym development, limited technology, narrative era, code rewriting, reaction technology, and toxicity elimination. Their main components are instantiated working with a few-shot prompting tactic, which permits us to use a few occasions to jumpstart the model’s understanding. Their iterative method, which features experiments, element assessment, a range of tasks, the era of useful feed-back, and stopping requirements, is intended to guide long run research in this field.
Their contributions, in temporary, are:
- To aid LLMs do improved on a wide variety of jobs, they propose SELF-REFINE, a exceptional technique that permits them to greatly enhance their success making use of their feedback continuously. Unlike previously endeavours, their approach necessitates a one LLM, which employs reinforcement studying or supervised instruction information.
- They perform comprehensive experiments on seven unique tasks—review rewriting, acronym technology, tale technology, code rewriting, reaction generation, constrained generation, and toxicity removal—and exhibit that SELF-REFINE performs at least 5% better—and occasionally up to additional than 40% better—than a immediate technology from effective generators like GPT-3.5 and even GPT-4.
Look at out the Paper, Code and Venture. All Credit history For This Study Goes To the Researchers on This Task. Also, don’t neglect to join our 18k+ ML SubReddit, Discord Channel, and E-mail E-newsletter, the place we share the most current AI study news, neat AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He is presently pursuing his undergraduate degree in Details Science and Synthetic Intelligence from the Indian Institute of Engineering(IIT), Bhilai. He spends most of his time doing work on jobs aimed at harnessing the power of device studying. His exploration fascination is graphic processing and is passionate about creating options about it. He loves to connect with people and collaborate on exciting jobs.
[ad_2]
Resource backlink