

[ad_1]
Developing synthetic units that see and realize the earth equally to human visible units is a crucial intention of personal computer eyesight. Recent progress in population mind activity measurement, alongside with improvements in the implementation and style of deep neural community types, have manufactured it attainable to specifically compare the architectural features of artificial networks to people of biological brains’ latent representations, revealing vital details about how these techniques get the job done. Reconstructing visible illustrations or photos from mind action, this kind of as that detected by practical magnetic resonance imaging (fMRI), is just one of these applications. This is a interesting but tough challenge mainly because the fundamental brain representations are mainly unidentified, and the sample size ordinarily applied for mind info is small.
Deep-discovering styles and methods, these kinds of as generative adversarial networks (GANs) and self-supervised studying, have not too long ago been utilized by lecturers to tackle this challenge. These investigations, even so, connect with for possibly wonderful-tuning towards the particular stimuli used in the fMRI experiment or teaching new generative models with fMRI details from scratch. These attempts have shown wonderful but constrained functionality in terms of pixel-intelligent and semantic fidelity, in component because of to the compact volume of neuroscience info and in part because of to the various challenges connected with constructing complicated generative products.
Diffusion Products, particularly the fewer computationally useful resource-intense Latent Diffusion Designs, are a new GAN substitute. Yet, as LDMs are nonetheless rather new, it is hard to have a total understanding of how they get the job done internally.
By applying an LDM known as Stable Diffusion to reconstruct visual photographs from fMRI alerts, a investigation crew from Osaka University and CiNet tried to handle the concerns pointed out higher than. They proposed a straightforward framework that can reconstruct higher-resolution images with significant semantic fidelity without having the need for complicated deep-discovering styles to be experienced or tuned.
The dataset employed by the authors for this investigation is the Organic Scenes Dataset (NSD), which delivers information gathered from an fMRI scanner across 30–40 periods throughout which every single issue considered 3 repeats of 10,000 visuals.
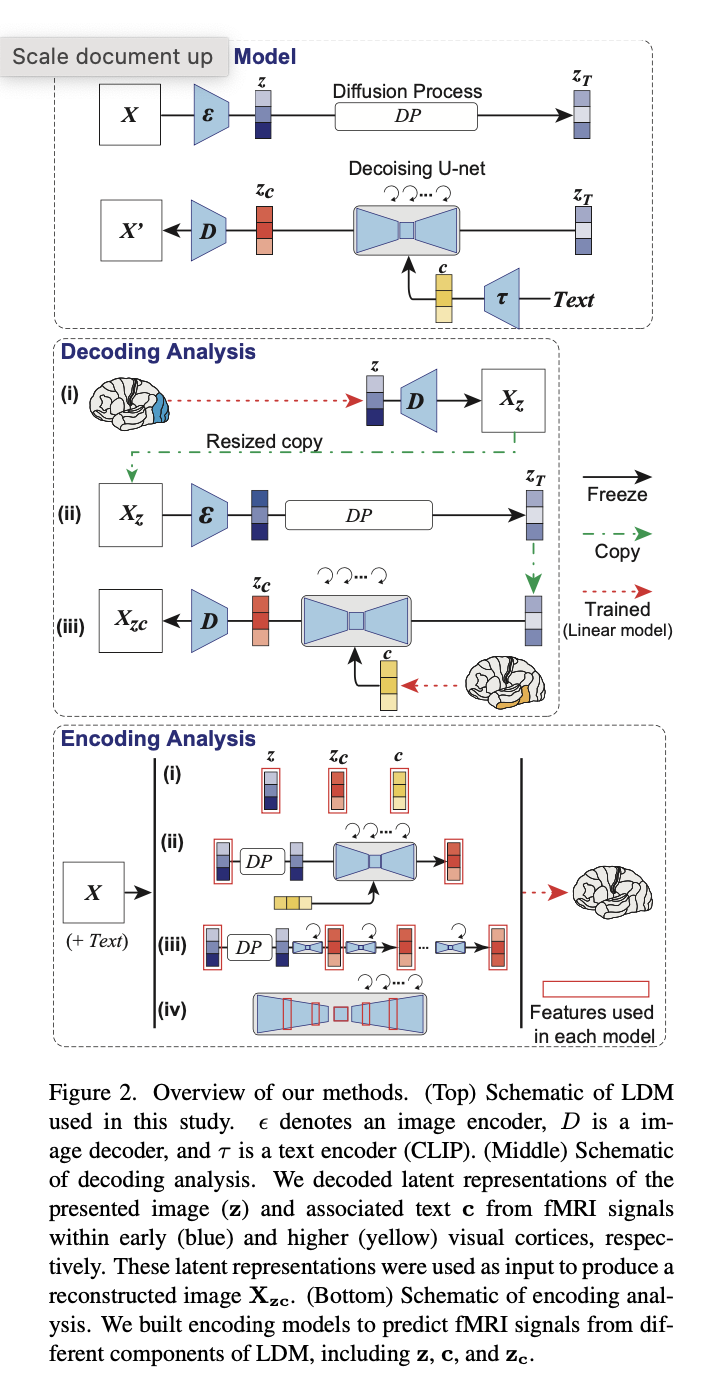
To start, they utilized a Latent Diffusion Product to build photographs from text. In the figure higher than (best), z is outlined as the created latent representation of z that has been modified by the product with c, c is outlined as the latent representation of texts (that explain the photos), and zc is outlined as the latent representation of the original picture that has been compressed by the autoencoder.
To examine the decoding model, the authors followed a few techniques (determine over, middle). To start with, they predicted a latent illustration z of the introduced impression X from fMRI alerts inside the early visible cortex (blue). z was then processed by a decoder to produce a coarse decoded image Xz, which was then encoded and handed by way of the diffusion method. Lastly, the noisy image was extra to a decoded latent text representation c from fMRI indicators within the increased visible cortex (yellow) and denoised to produce zc. From, zc a decoding module manufactured a remaining reconstructed impression Xzc. It’s essential to underline that the only schooling required for this method is to linearly map fMRI signals to LDM components, zc, z and c.
Setting up from zc, z and c the authors performed an encoding investigation to interpret the inner functions of LDMs by mapping them to brain exercise (determine over, bottom). The outcomes of reconstructing pictures from representations are revealed down below.

Visuals that have been recreated employing basically z experienced a visual consistency with the original photographs, but their semantic price was dropped. On the other hand, photos that ended up only partially reconstructed working with c yielded pictures that had excellent semantic fidelity but inconsistent visuals. The validity of this technique was demonstrated by the ability of images recovered employing zc to produce high-resolution illustrations or photos with excellent semantic fidelity.
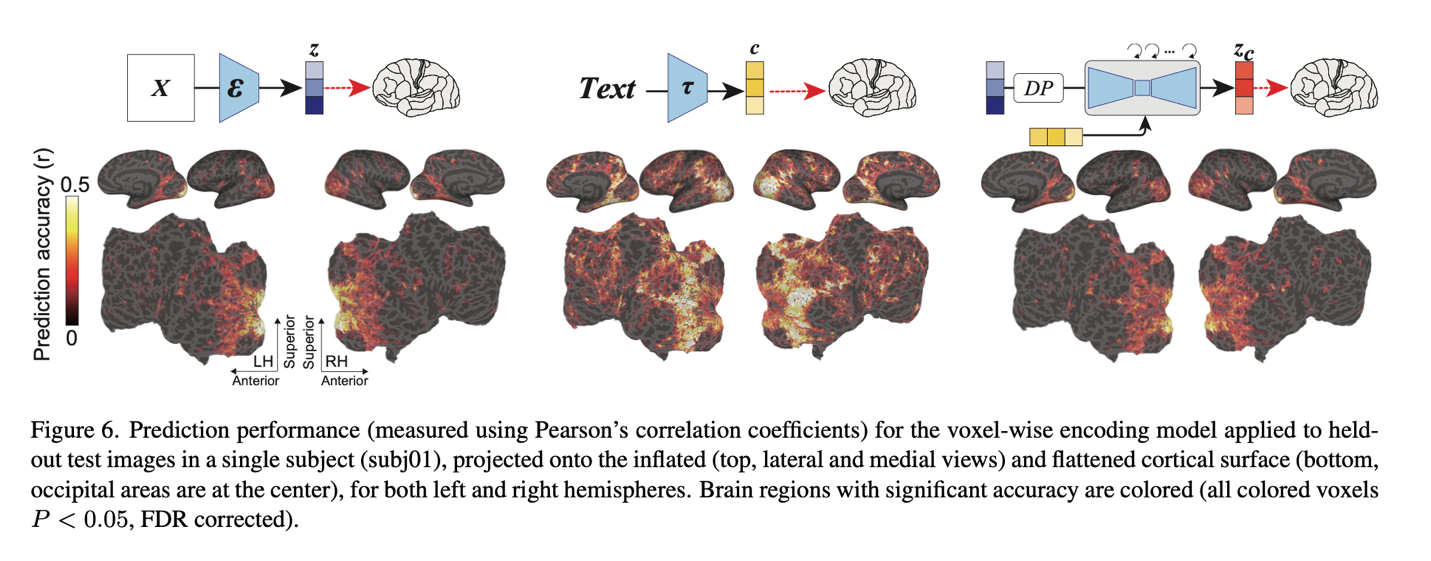
The ultimate evaluation of the mind reveals new info about DM models. At the back of the brain, the visual cortex, all three parts attained good prediction overall performance. Particularly, z supplied sturdy prediction functionality in the early visible cortex, which lies in the again of the visible cortex. Also, it shown robust prediction values in the higher visual cortex, which is the anterior part of the visual cortex, but smaller values in other areas. On the other hand, in the upper visible cortex, c led to the greatest prediction general performance.
Examine out the Paper and Job Web page. All Credit For This Investigation Goes To the Researchers on This Job. Also, don’t fail to remember to join our 16k+ ML SubReddit, Discord Channel, and E-mail E-newsletter, exactly where we share the newest AI investigation news, awesome AI tasks, and a lot more.
Leonardo Tanzi is at this time a Ph.D. University student at the Polytechnic University of Turin, Italy. His current investigation focuses on human-device methodologies for sensible support in the course of advanced interventions in the medical domain, applying Deep Discovering and Augmented Fact for 3D guidance.
[ad_2]
Resource connection