
[ad_1]
Major foundational products like CLIP, Stable Diffusion, and Flamingo have radically improved multimodal deep learning in excess of the previous few decades. Joint textual content-picture modeling has absent from remaining a market software to a single of the (if not the) most pertinent concerns in today’s synthetic intelligence landscape thanks to the superb abilities of these designs to deliver impressive, superior-resolution imagery or carry out tricky downstream issues. Astonishingly, inspite of tackling vastly distinctive jobs and acquiring vastly unique styles, all these models have a few elementary houses in common that add to their powerful effectiveness: a very simple and stable goal operate throughout (pre-)teaching, a properly-investigated scalable product architecture, and – maybe most importantly – a big, assorted dataset.
Multimodal deep understanding, as of 2023, is nevertheless mostly anxious with textual content-image modeling, with only limited notice paid out to more modalities like online video (and audio). Considering that the tactics employed to prepare the models are normally modality agnostic, a person could speculate why there aren’t strong groundwork products for these other modalities. The uncomplicated rationalization is the scarcity of significant-high quality, huge-scale annotated datasets. This lack of clean data impedes investigate and development of large multimodal styles, primarily in the video domain, in distinction to picture modeling, in which there exist founded datasets for scaling like LAION-5B, DataComp, and COYO-700M and scalable instruments like img2dataset.
Due to the fact it can pave the way for groundbreaking initiatives like high-high quality online video and audio creation, enhanced pre-skilled products for robotics, movie Advert for the blind community, and far more, researchers propose that resolving this facts challenge is a central aim of (open resource) multimodal investigate.
Scientists present movie2dataset, an open-supply system for rapidly and intensive video clip and audio dataset curating. It has been properly analyzed on many massive video datasets, and it is adaptable, extensible, and delivers a massive selection of transformations. You can discover these scenario scientific tests and in depth instructions on replicating our process in the repository.
By downloading person video datasets, merging them, and reshaping them into more manageable shapes with new features and considerably far more samples, scientists have utilized video clip2dataset to develop on existing video clip datasets. Make sure you refer to the illustrations part for a more in-depth description of this chain processing. The outcomes they accomplished by instruction distinct versions on the datasets equipped by online video2dataset exhibit the tool’s efficacy. Our forthcoming review will extensively talk about the new knowledge set and involved results.
To begin, let us define online video2dataset.
Since webdataset is an satisfactory input_format, online video2dataset can be applied in a chain to reprocess earlier downloaded facts. You can use the WebVid info you downloaded in the previous illustration to execute this script, which will compute the optical stream for every single motion picture and keep it in metadata shards (shards that only have the optical stream metadata in them).
Architecture
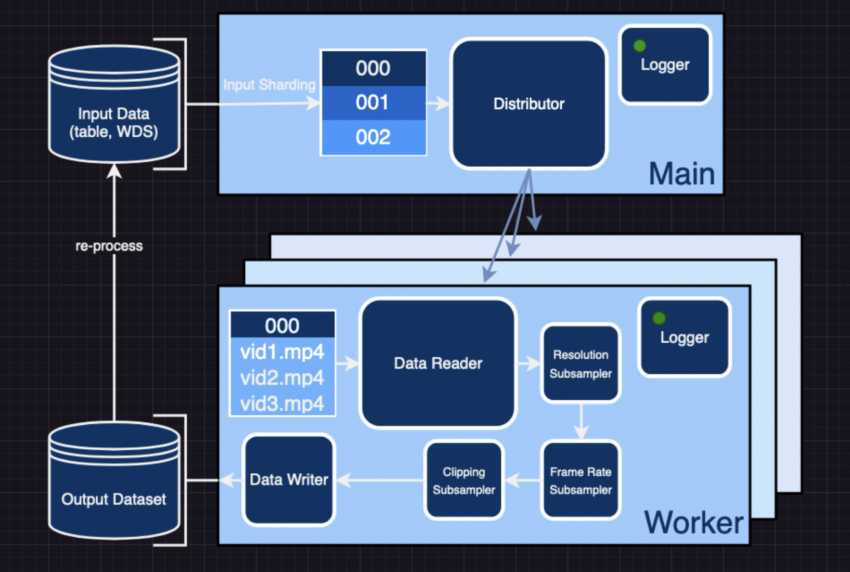
Dependent on img2dataset, movie2dataset normally takes a checklist of URLs and related metadata and converts it into a WebDataset that can be loaded with a solitary command. In addition, the WebDataset can be reprocessed for more changes with the similar shard contents preserved. How does movie2dataset get the job done? I’ll describe.
Exchanging Concepts
The initial phase is to partition the input details so that it could be distributed evenly among the the employees. These enter shards are cached briefly, and the a person-to-one particular mapping involving them and their corresponding output shards assures fault-free recovery. If a dataset processing operate terminates unexpectedly, one particular can help you save time by skipping the input shards for which scientists already have the corresponding output shard.
Conversation and Research
Workers then acquire turns reading through and processing the samples contained inside the shards. Researchers present a few various distribution modes: multiprocessing, pyspark, and slurm. The previous is ideal for single-machine apps, even though the latter is practical for scaling across quite a few machines. The format of the incoming dataset decides the reading through approach. If the details is a table of URLs, movie2dataset will fetch the video clip from the net and include it to the dataset. movie2dataset works with a lot of distinct movie platforms because it uses yt-dlp to ask for movies it just can’t discover. Nonetheless, if the video clip samples appear from an current Internet dataset, the data loader for that dataset can study the tensor format of the bytes or frames.
Subsampling
Just after the online video has been read through and the employee has the movie bytes, the bytes are despatched by means of a pipeline of subsamplers according to the position configuration. In this phase, the movie may perhaps be optionally downsampled in terms of both of those frame price and resolution clipped scenes might be identified and so on. On the other hand, there are subsamplers whose sole intent is to extract and increase metadata, these types of as resolution/compression data, synthetic captions, optical move, and so on, from the input modalities. Defining a new subsampler or modifying an existing a person is all it takes to add a new transformation to video2dataset if it isn’t previously there. This is a large assistance and can be applied with a few alterations somewhere else in the repository.
Logging
Online video2dataset retains meticulous logs at various details in the system. Every shard’s completion results in its affiliated “ID” _stats.json file. Information and facts this sort of as the complete number of samples dealt with, the proportion of people taken care of properly, and the occurrence and mother nature of any faults are recorded below. Weights & Biases (wand) is an additional software that can be utilized with video clip2dataset. With just just one argument, you can transform on this integration and entry thorough overall performance reporting and metrics for successes and failures. Such abilities are handy for benchmarking and charge-estimating responsibilities related to entire work opportunities.
Writing
Finally, video2dataset retailers the modified data in output shards at person-specified places to use in subsequent coaching or reprocessing functions. The dataset can be downloaded in quite a few formats, all consisting of shards with N samples each. These formats include folders, tar data files, documents, and parquet files. The most critical types are the directories format for more compact datasets for debugging and tar information used by the WebDataset format for loading.
Reprocessing
video2dataset can reprocess earlier output datasets by reading the output shards and passing the samples via new transformations. This operation is specifically beneficial for movie datasets, taking into consideration their typically hefty size and awkward nature. It permits us to cautiously downsample the data to stay clear of numerous downloads of large datasets. Scientists dig into a functional case in point of this in the future section.
Code and aspects can be located in GitHub https://github.com/iejMac/video2dataset
Upcoming Plans
- Review of a enormous dataset constructed with the software package described in this website posting, adopted by public dissemination of the benefits of that analyze.
- It improved synthetic captioning. There is a good deal of space for innovation in artificial captioning for videos. Soon in video clip2dataset, researchers will have much more exciting procedures to create captions for video clips that use image captioning versions and LLMs.
- Whisper’s ability to extract quite a few text tokens from the movie has been the issue of substantially dialogue given that its launch. Utilizing online video2dataset, they are at this time transcribing a sizable assortment of podcasts to make the ensuing textual content dataset (focusing on 50B tokens) publicly available.
- Lots of exciting modeling strategies. With any luck ,, with improved dataset curation tooling, far more men and women will attempt to drive the SOTA in the movie and audio modality.
video2dataset is a fully open up-resource project, and researchers are fully commited to developing it in the open. This implies all the relevant TODOs and potential directions can be located in the troubles tab of the repository. Contributions are welcomed the ideal way to do that is to decide on out a difficulty, address it, and submit a pull request.
Verify out the Web site and Github Link. Don’t forget about to join our 26k+ ML SubReddit, Discord Channel, and Electronic mail Publication, in which we share the latest AI exploration news, amazing AI jobs, and far more. If you have any issues pertaining to the higher than short article or if we skipped just about anything, come to feel totally free to e mail us at [email protected]
🚀 Check out Out 100’s AI Resources in AI Instruments Club
Dhanshree Shenwai is a Computer Science Engineer and has a great working experience in FinTech providers masking Fiscal, Cards & Payments and Banking area with eager desire in purposes of AI. She is enthusiastic about discovering new technologies and advancements in today’s evolving planet creating everyone’s existence easy.
[ad_2]
Resource link