

[ad_1]
DeepNash learns to perform Stratego from scratch by combining match theory and model-no cost deep RL
Activity-enjoying artificial intelligence (AI) devices have state-of-the-art to a new frontier. Stratego, the basic board sport that’s much more complex than chess and Go, and craftier than poker, has now been mastered. Printed in Science, we existing DeepNash, an AI agent that uncovered the game from scratch to a human specialist degree by taking part in towards by itself.
DeepNash employs a novel approach, centered on game theory and model-free of charge deep reinforcement learning. Its enjoy fashion converges to a Nash equilibrium, which usually means its participate in is incredibly difficult for an opponent to exploit. So tough, in point, that DeepNash has attained an all-time major-3 rating among human professionals on the world’s largest on the internet Stratego platform, Gravon.
Board game titles have traditionally been a evaluate of progress in the discipline of AI, letting us to examine how people and devices establish and execute techniques in a managed surroundings. Contrary to chess and Go, Stratego is a match of imperfect information and facts: players simply cannot straight notice the identities of their opponent’s pieces.
This complexity has meant that other AI-based Stratego systems have struggled to get over and above novice stage. It also indicates that a very effective AI approach identified as “game tree search”, previously made use of to learn a lot of games of ideal facts, is not sufficiently scalable for Stratego. For this purpose, DeepNash goes much outside of sport tree look for altogether.
The value of mastering Stratego goes outside of gaming. In pursuit of our mission of solving intelligence to progress science and reward humanity, we will need to construct superior AI methods that can operate in intricate, serious-entire world situations with minimal data of other brokers and men and women. Our paper demonstrates how DeepNash can be used in conditions of uncertainty and productively stability results to aid solve advanced difficulties.
Finding to know Stratego
Stratego is a transform-primarily based, capture-the-flag game. It’s a video game of bluff and tactics, of facts gathering and subtle manoeuvring. And it’s a zero-sum game, so any gain by a person participant represents a decline of the same magnitude for their opponent.
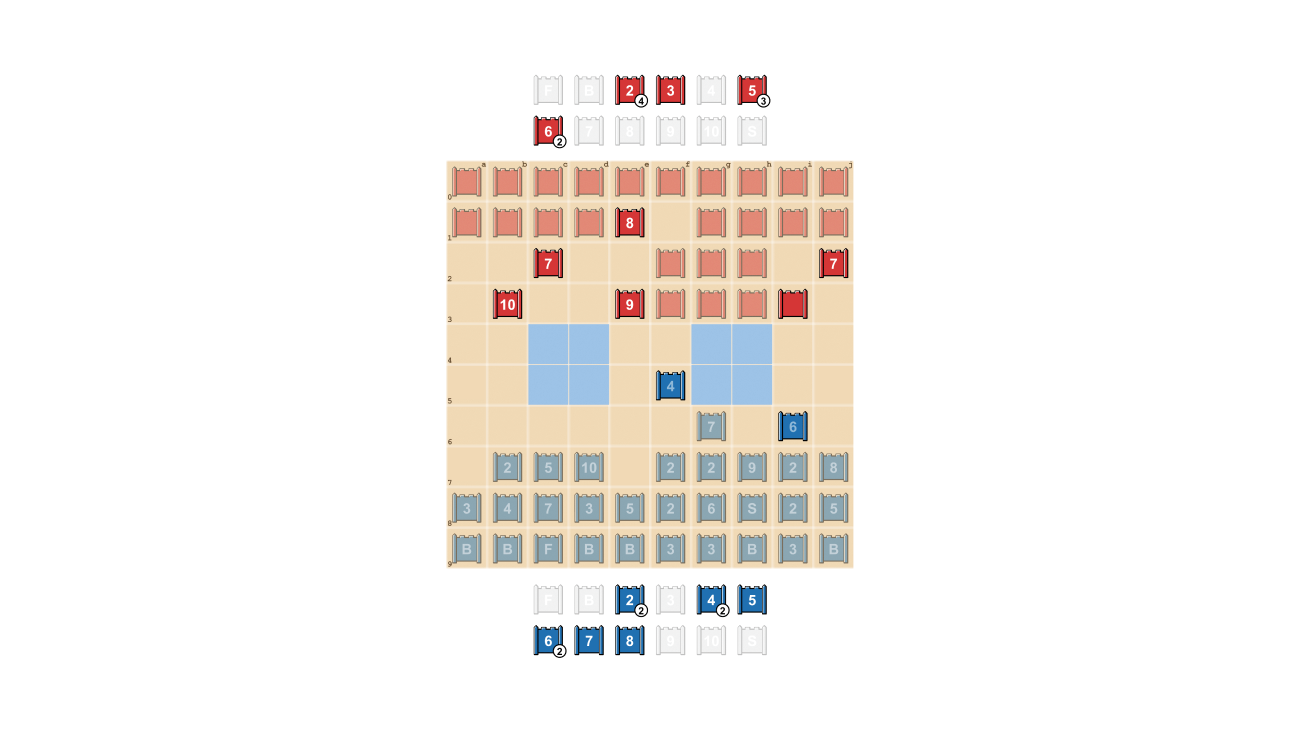
Stratego is tough for AI, in section, due to the fact it’s a video game of imperfect information and facts. Each players start out by arranging their 40 enjoying pieces in what ever starting up development they like, originally concealed from a single yet another as the video game begins. Due to the fact equally gamers never have obtain to the similar information, they need to stability all attainable outcomes when producing a selection – offering a complicated benchmark for learning strategic interactions. The styles of parts and their rankings are shown beneath.

Middle: A possible starting off development. Notice how the Flag is tucked away safely at the back, flanked by protecting Bombs. The two pale blue spots are “lakes” and are under no circumstances entered.
Right: A recreation in participate in, demonstrating Blue’s Spy capturing Red’s 10.
Information and facts is really hard gained in Stratego. The id of an opponent’s piece is generally revealed only when it meets the other participant on the battlefield. This is in stark contrast to video games of excellent details these types of as chess or Go, in which the area and identity of just about every piece is identified to the two gamers.
The equipment studying methods that do the job so very well on best facts game titles, these kinds of as DeepMind’s AlphaZero, are not quickly transferred to Stratego. The need to have to make decisions with imperfect info, and the opportunity to bluff, would make Stratego far more akin to Texas hold’em poker and involves a human-like ability when pointed out by the American author Jack London: “Life is not normally a make any difference of keeping good playing cards, but occasionally, actively playing a inadequate hand properly.”
The AI techniques that work so perfectly in game titles like Texas hold’em never transfer to Stratego, however, mainly because of the sheer size of the video game – typically hundreds of moves ahead of a player wins. Reasoning in Stratego must be carried out above a large number of sequential steps with no noticeable insight into how each and every motion contributes to the last consequence.
Finally, the quantity of feasible match states (expressed as “game tree complexity”) is off the chart in comparison with chess, Go and poker, earning it very difficult to fix. This is what thrilled us about Stratego, and why it has represented a a long time-extensive challenge to the AI neighborhood.
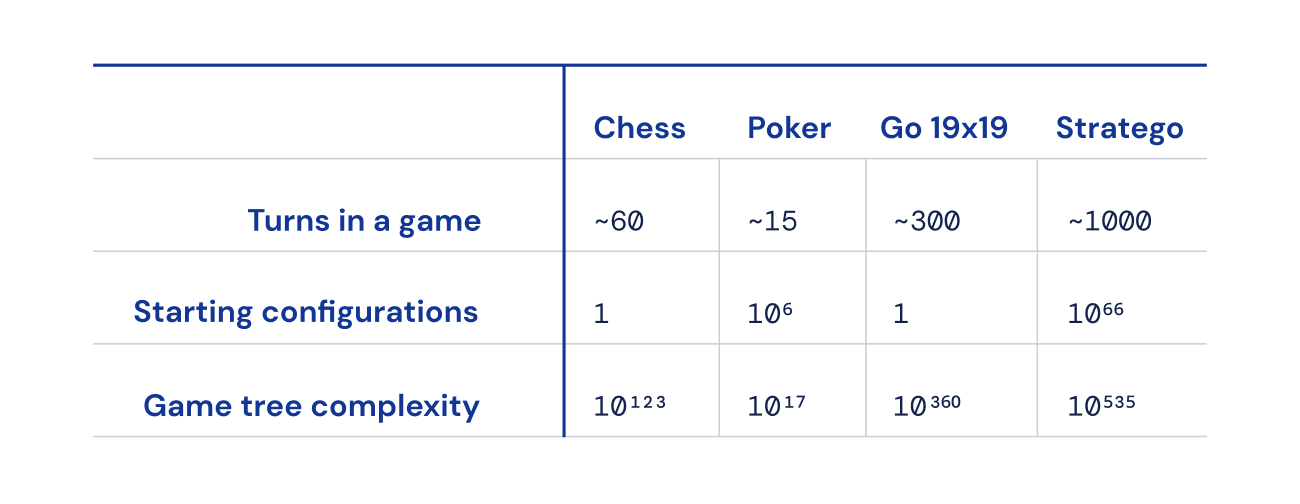
Searching for an equilibrium
DeepNash employs a novel approach dependent on a combination of game theory and model-cost-free deep reinforcement finding out. “Model-free” usually means DeepNash is not trying to explicitly product its opponent’s personal game-state all through the video game. In the early phases of the game in unique, when DeepNash is aware minimal about its opponent’s items, this kind of modelling would be ineffective, if not unachievable.
And for the reason that the recreation tree complexity of Stratego is so large, DeepNash are unable to employ a stalwart method of AI-primarily based gaming – Monte Carlo tree search. Tree look for has been a key component of several landmark achievements in AI for a lot less elaborate board game titles, and poker.
Instead, DeepNash is run by a new sport-theoretic algorithmic thought that we’re contacting Regularised Nash Dynamics (R-NaD). Doing the job at an unparalleled scale, R-NaD steers DeepNash’s discovering conduct toward what is recognized as a Nash equilibrium (dive into the complex aspects in our paper).
Activity-taking part in conduct that results in a Nash equilibrium is unexploitable over time. If a particular person or machine performed completely unexploitable Stratego, the worst earn amount they could reach would be 50%, and only if dealing with a equally best opponent.
In matches towards the ideal Stratego bots – like many winners of the Personal computer Stratego Planet Championship – DeepNash’s get charge topped 97%, and was often 100%. In opposition to the prime qualified human gamers on the Gravon online games platform, DeepNash achieved a acquire price of 84%, earning it an all-time major-a few rating.
Be expecting the unanticipated
To realize these outcomes, DeepNash shown some remarkable behaviours each all through its preliminary piece-deployment phase and in the gameplay phase. To become tricky to exploit, DeepNash formulated an unpredictable technique. This signifies creating initial deployments assorted sufficient to stop its opponent spotting styles in excess of a sequence of online games. And during the sport section, DeepNash randomises concerning seemingly equivalent steps to protect against exploitable tendencies.
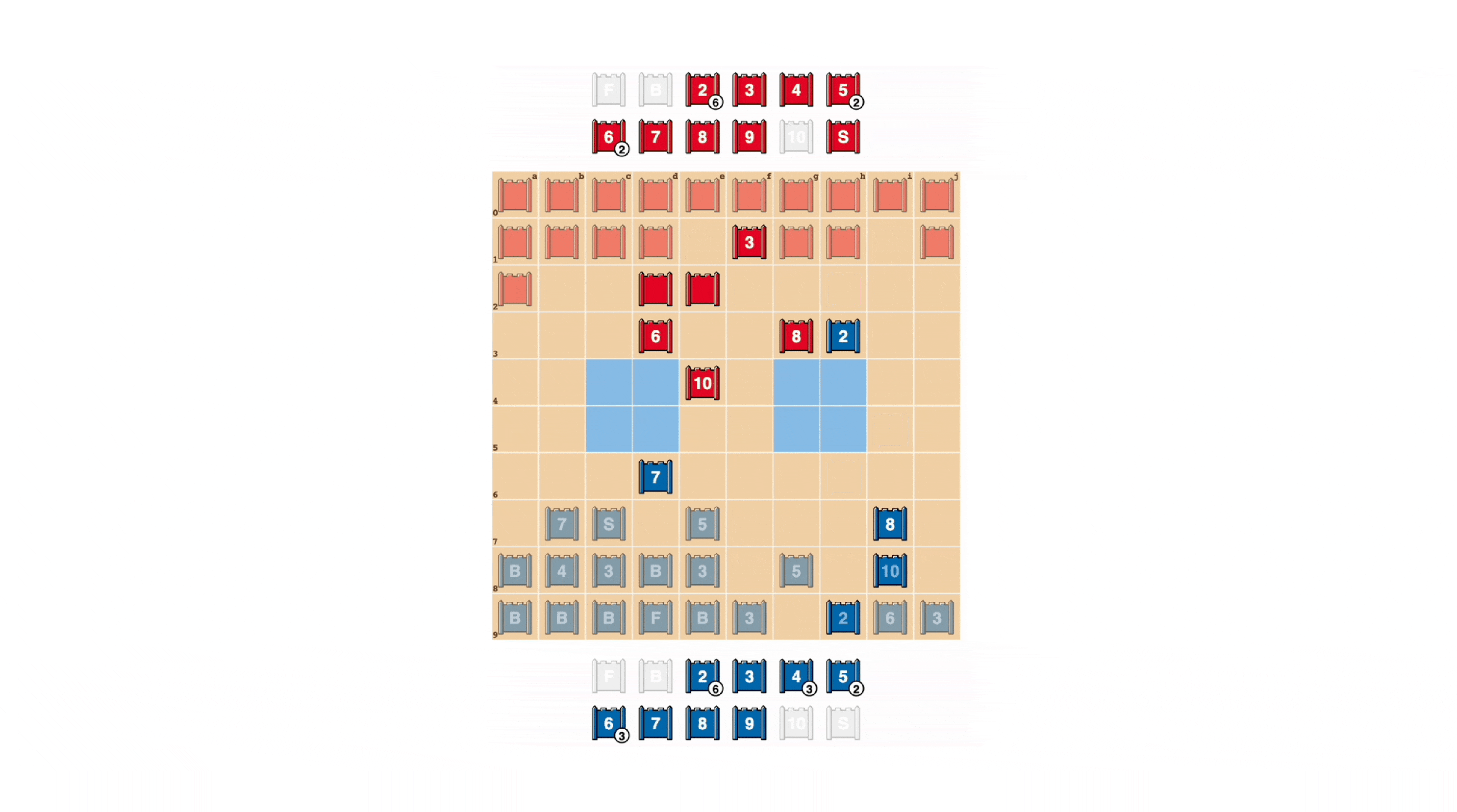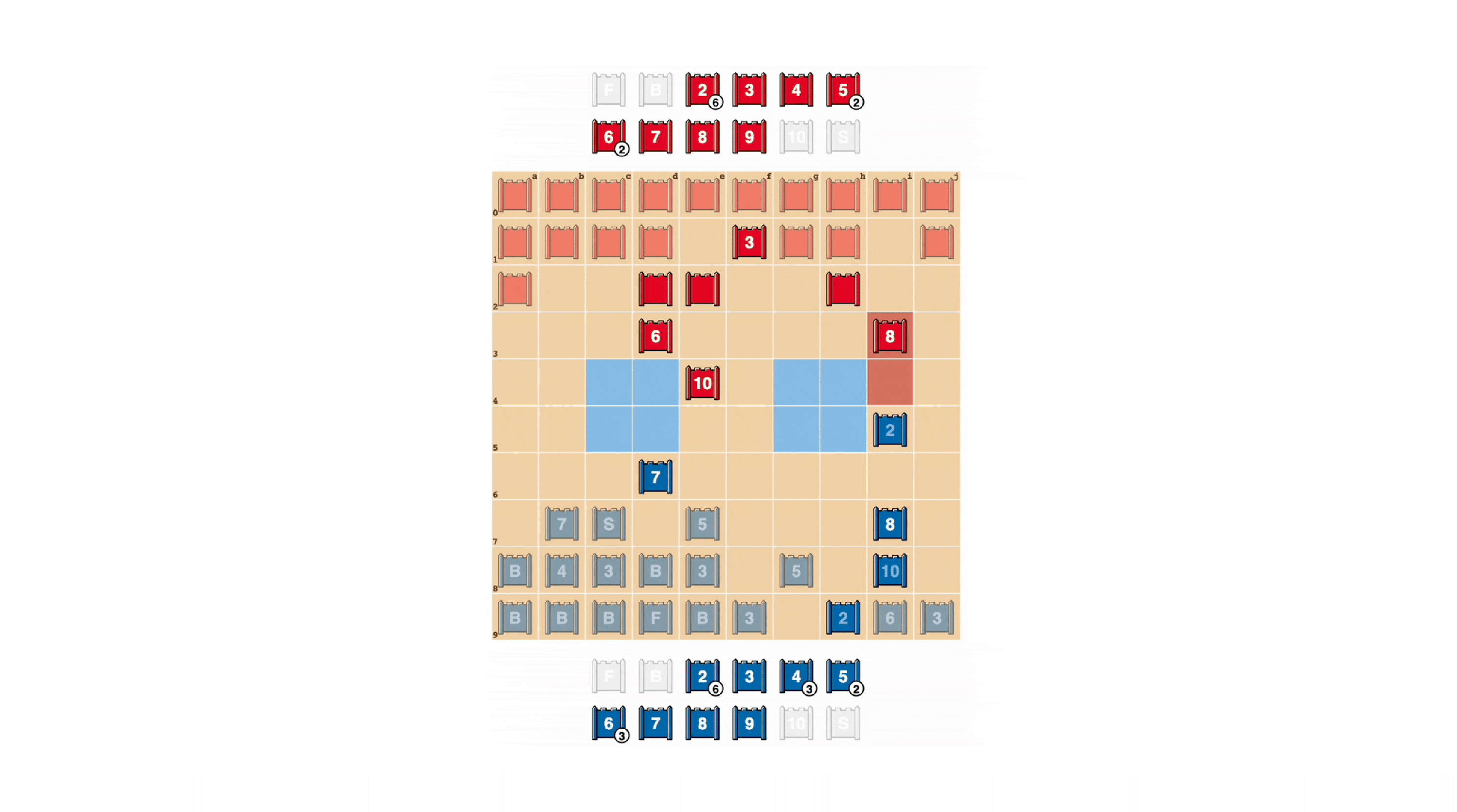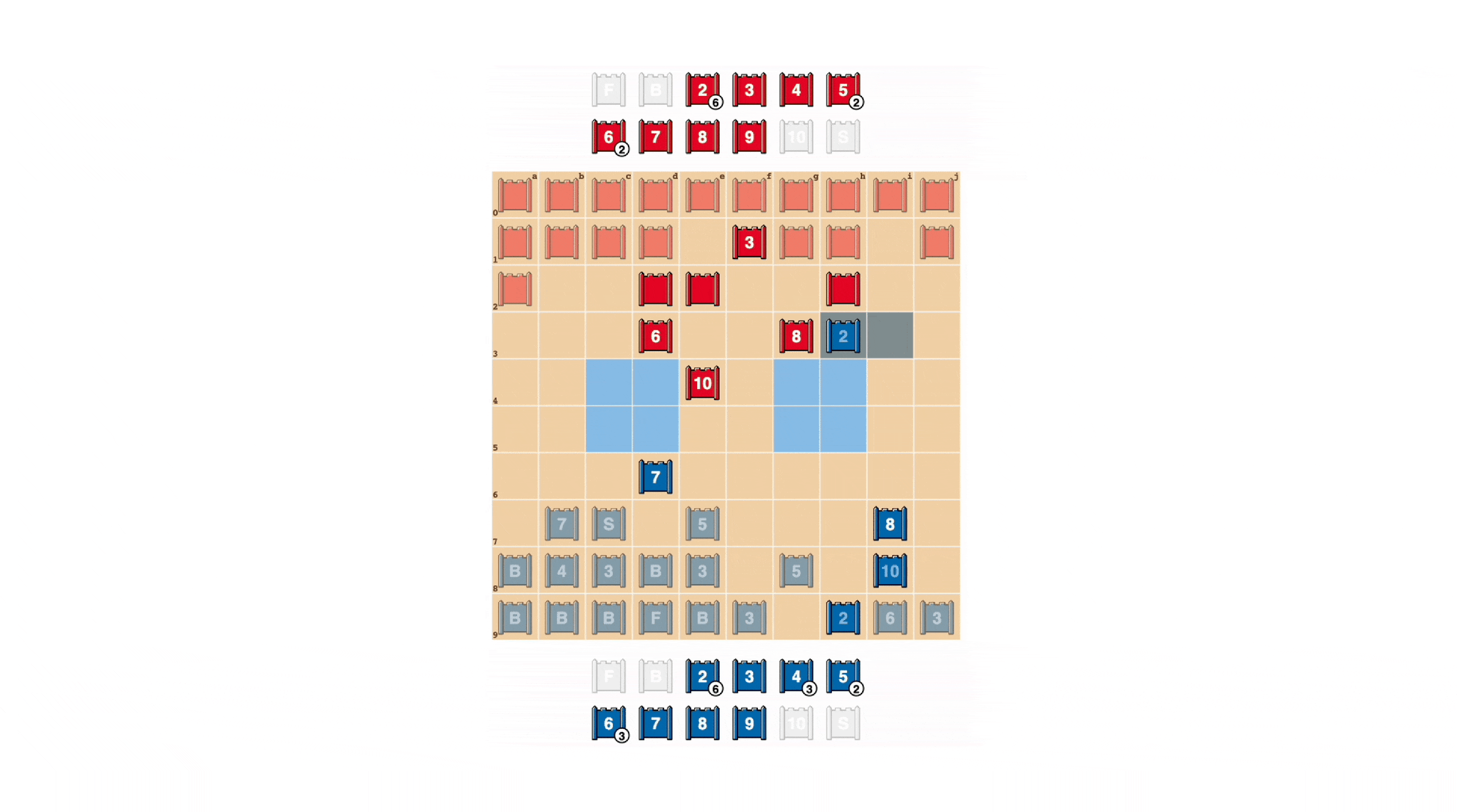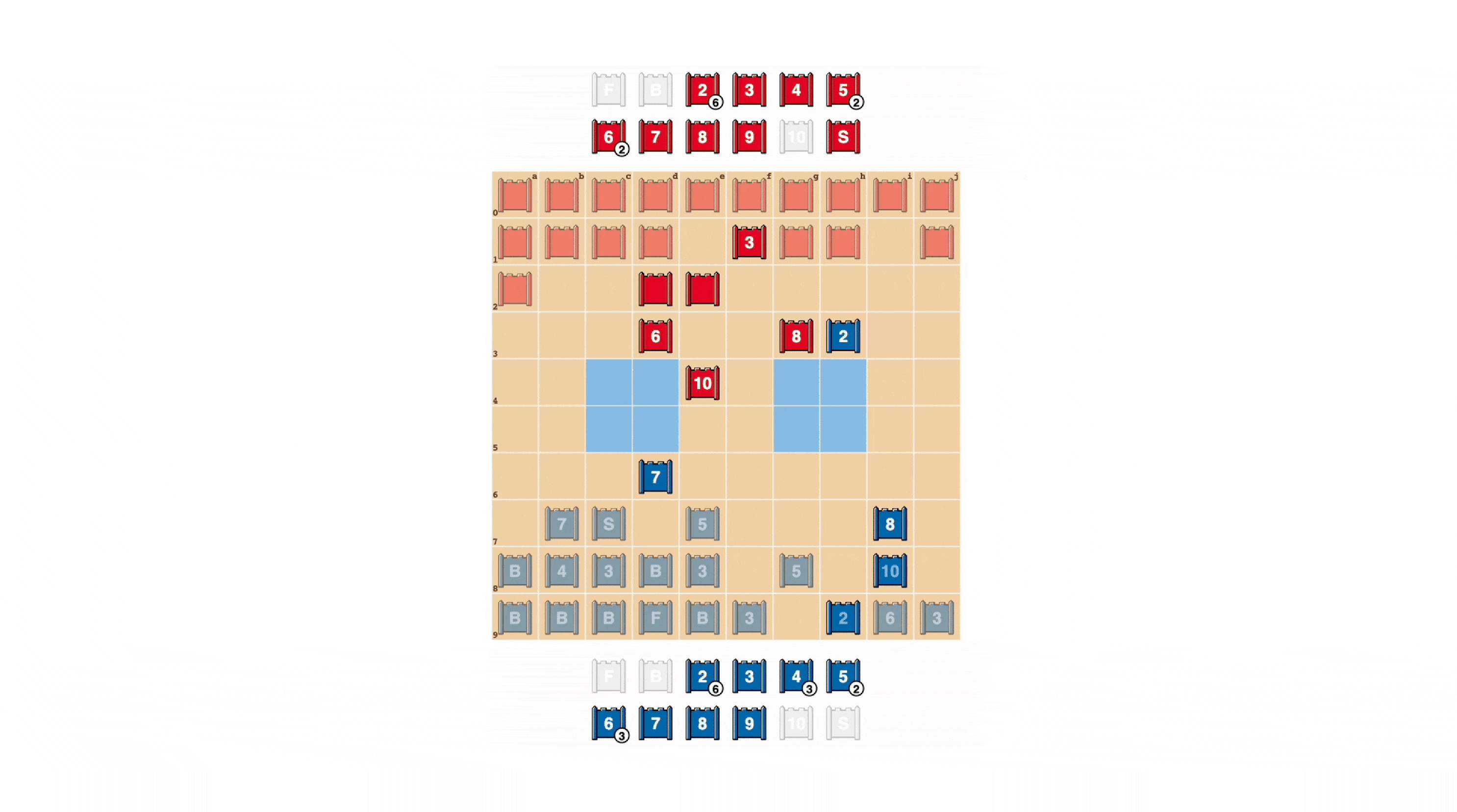
Stratego players try to be unpredictable, so there is benefit in trying to keep info hidden. DeepNash demonstrates how it values facts in pretty placing means. In the case in point underneath, from a human player, DeepNash (blue) sacrificed, among other items, a 7 (Main) and an 8 (Colonel) early in the match and as a outcome was able to track down the opponent’s 10 (Marshal), 9 (Common), an 8 and two 7’s.
These efforts still left DeepNash at a significant materials disadvantage it dropped a 7 and an 8 even though its human opponent preserved all their pieces rated 7 and above. Even so, getting strong intel on its opponent’s top brass, DeepNash evaluated its winning prospects at 70% – and it won.
The art of the bluff
As in poker, a excellent Stratego participant should often characterize toughness, even when weak. DeepNash acquired a wide range of these types of bluffing practices. In the instance down below, DeepNash takes advantage of a 2 (a weak Scout, not known to its opponent) as if it ended up a high-position piece, pursuing its opponent’s identified 8. The human opponent decides the pursuer is most most likely a 10, and so tries to lure it into an ambush by their Spy. This tactic by DeepNash, risking only a minor piece, succeeds in flushing out and eradicating its opponent’s Spy, a critical piece.
See extra by watching these four video clips of total-size video games performed by DeepNash in opposition to (anonymised) human professionals: Sport 1, Recreation 2, Activity 3, Activity 4.
“The degree of perform of DeepNash surprised me. I had by no means listened to of an artificial Stratego player that came close to the amount needed to win a match in opposition to an expert human player. But immediately after actively playing against DeepNash myself, I was not astonished by the top-3 position it later on obtained on the Gravon platform. I count on it would do very well if allowed to take part in the human Globe Championships.”
– Vincent de Boer, paper co-author and former Stratego Environment Winner
Future directions
When we created DeepNash for the really defined planet of Stratego, our novel R-NaD process can be immediately utilized to other two-player zero-sum video games of the two best or imperfect data. R-NaD has the possible to generalise far over and above two-player gaming configurations to address substantial-scale genuine-world issues, which are normally characterised by imperfect data and astronomical state areas.
We also hope R-NaD can help unlock new programs of AI in domains that aspect a massive quantity of human or AI participants with different plans that may not have details about the intention of others or what’s developing in their surroundings, this kind of as in the substantial-scale optimisation of website traffic administration to cut down driver journey occasions and the affiliated vehicle emissions.
In producing a generalisable AI procedure that’s strong in the experience of uncertainty, we hope to bring the issue-solving capabilities of AI additional into our inherently unpredictable entire world.
Understand additional about DeepNash by looking at our paper in Science.
For scientists fascinated in offering R-NaD a test or performing with our freshly proposed system, we’ve open up-sourced our code.
[ad_2]
Resource connection