
[ad_1]
An important purpose in the analyze of personal computer eyesight is to comprehend visible cases. Around the several years, various proxy tasks—from photo-level jobs like classification to dense prediction tasks like item recognition, segmentation, and depth prediction—have been created to evaluate how proficiently types properly understand the contents of an picture. These benchmarks serve as a valuable north star for researchers seeking to build better visual being familiar with methods. On the other hand, a single drawback of these traditional pc eyesight benchmarks is that they usually confine their label sets to a predetermined lexicon of concepts. As a final result, there are inherent biases and blind spots in the competencies that may be obtained and utilised to consider versions.
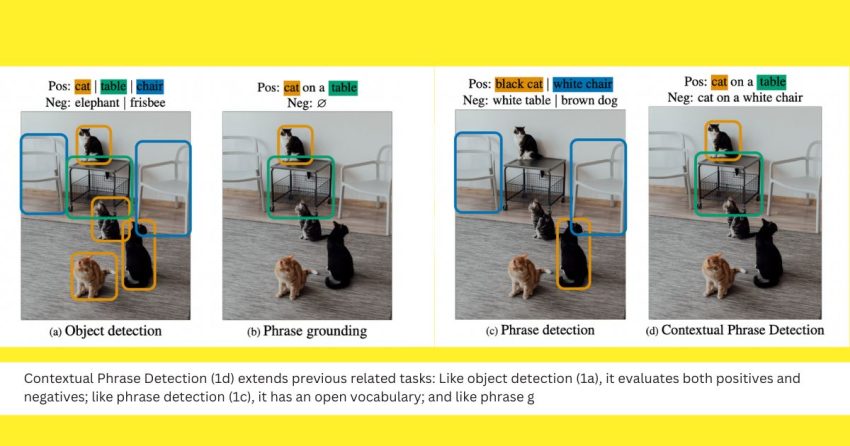
Creating benchmarks that use purely natural language to elicit a model’s comprehension of a particular impression more nuancedly is a single way to loosen up this limited formulation. Impression captioning is a single of the oldest of these responsibilities, adopted by many many others, together with Visual Query Answering (VQA), Visual Commonsense Reasoning (VCR), and Visible Entailment (VE), between other individuals. They are notably intrigued in challenges like phrase grounding and reference expression comprehension (REC) that take a look at a model’s wonderful-grained localization competencies. Whilst they are a sensible extension of classical object detection, these jobs are only localization relatively than real item detection because they presume that the products of desire are noticeable in the photo. They deliver a bridge between these two classes of responsibilities in their study, which they refer to as contextual phrase detection (CPD).
When employed in CPD, versions are provided just one or far more phrases that might be a element of a more time textual context. The product should come across all occurrences of every term if and only if they in good shape within the context established by the full sentence. For occasion, they inquire the product to predict containers for every cat and any table when there is a cat on the desk and for no other item provided the assertion “cat on a table” (including other cats or tables that may well exist in the image see Determine 1d). Importantly, they do not imply a priori that all phrases are groundable, compared with REC and phrase grounding. When this premise is relaxed, the product is tested to see if it can end predicting boxes when no item fulfills all of the sentence’s restrictions.
Acquiring express damaging certificates for a word supplied a picture is essential for reliably testing the model’s capacity to discern whether or not the item described by the phrase is existing in the impression. Since the means to achieve the trouble involves information of both of those localization (exactly where the items are) and classification (is the indicated item present? ), this might be deemed a true extension of the object detection job. With CPD, styles may well now be benchmarked for detecting anything that can be explained in the totally free-sort textual content with no remaining limited by the vocabulary, giving models’ detection abilities a probability to be evaluated flexibly. They publish TRICD, a human-annotated assessment dataset comprising 2672 picture-text pairings with 1101 distinct phrases joined to a total of 6058 bounding boxes, to facilitate the evaluation of this modern position.

They include this new restriction to the previously makes an attempt at open up-finished detection. They chose a federated approach given that it is unachievable to deliver adverse certifications for all the words in all the images. For every favourable phrase, they meticulously choose a similar “distractor” graphic in which the concentrate on phrase does not seem. The major challenge is getting and verifying these damaging illustrations, especially people that can check a model’s discriminative skills.
They find out that, based on their situations, models often mistakenly establish things when they surface in unexpected cases or hallucinate nonexistent objects. The outcomes of this study are identical to hallucination phenomena in image captioning units. For instance, SoTA VQA types like FIBER, OFA, and Flamingo-3B all answer “yes” to the thoughts “Is there a person rowing a boat in the river?” and “Is there a baseball bat?” with regards to Fig. 2a and Fig. 2b, respectively. Predicting bounding packing containers needs CPD and enables a more granular insight into VL model failure mechanisms and believed processes.
They find out that, dependent on their conditions, styles routinely mistakenly detect items when they surface in sudden situations or hallucinate nonexistent objects. The success of this examine are equivalent to hallucination phenomena in image captioning methods. For instance, SoTA VQA styles like FIBER, OFA, and Flamingo-3B all answer “yes” to the thoughts “Is there a man or woman rowing a boat in the river?” and “Is there a baseball bat?” relating to Fig. 2a and Fig. 2b, respectively. Predicting bounding containers involves CPD and allows a more granular perception into VL product failure mechanisms and imagined procedures.

They clearly show a huge functionality gap (∼10 points) among the evaluated models’ overall performance on TRICD compared to benchmarks like GQA and Flickr30k in terms of F1-rating on binary issues and phrase grounding remember@1, respectively, indicating that their dataset is tough. On the CPD activity, the finest product achieves 21.5 AP on TRICD. They take a look at failure instances and obtain sizeable area for advancement in SoTA models’ abilities to fully grasp contextual cues. They hope that TRICD serves to improved evaluate development in creating visual being familiar with versions obtaining wonderful-grained spatial and relational understanding. Additional examples can be observed on their challenge web-site.
Check out out the Paper, Challenge and Github. All Credit score For This Analysis Goes To the Scientists on This Job. Also, really don’t forget about to join our 14k+ ML SubReddit, Discord Channel, and Email E-newsletter, the place we share the newest AI investigate news, interesting AI initiatives, and much more.
Aneesh Tickoo is a consulting intern at MarktechPost. He is now pursuing his undergraduate diploma in Information Science and Artificial Intelligence from the Indian Institute of Technological know-how(IIT), Bhilai. He spends most of his time operating on jobs aimed at harnessing the ability of device discovering. His investigation desire is image processing and is passionate about constructing solutions close to it. He loves to join with persons and collaborate on intriguing tasks.
[ad_2]
Supply connection