
[ad_1]
Around the past decade, instruction larger sized and far more in excess of parametrized networks, or the “stack extra layers” tactic, has turn into the norm in equipment mastering. As the threshold for a “large network” has elevated from 100 million to hundreds of billions of parameters, most investigation teams have observed the computing fees related with education this kind of networks too significant to justify. Inspite of this, there is a lack of theoretical knowledge of the need to have to educate designs that can have orders of magnitude much more parameters than the education instances.
Far more compute-productive scaling optima, retrieval-augmented designs, and the clear-cut system of training smaller sized styles for lengthier have all provided new intriguing trade-offs as alternate ways to scaling. Nevertheless, they rarely democratize the schooling of these versions and do not help us comprehend why over-parametrized designs are essential.
Overparametrization is also not needed for training, according to a lot of new reports. Empirical proof supports the Lottery Ticket Hypothesis, which states that, at some level in initialization (or early training), there are isolated sub-networks (successful tickets) that, when educated, realize the complete network’s functionality.
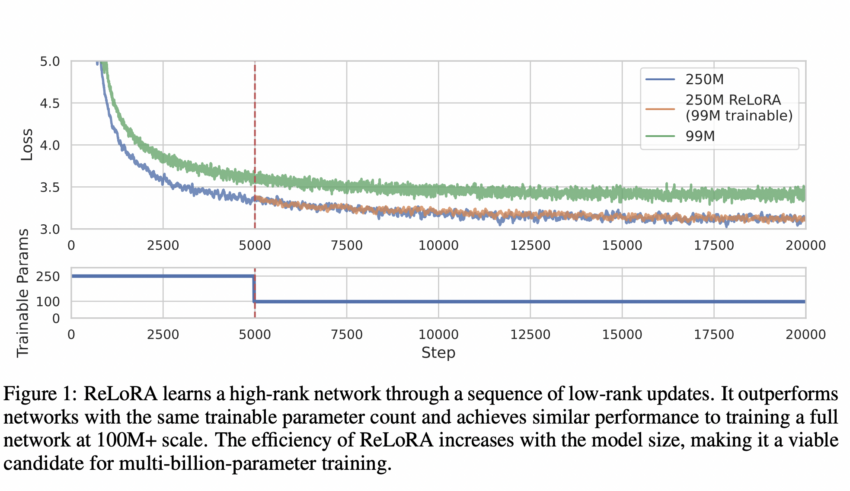
Current research by the College of Massachusetts Lowell introduced ReLoRA to remedy this challenge by using the rank of sum house to practice a substantial-rank network with a series of small-rank updates. Their results demonstrate that ReLoRA is capable of a high-rank update and delivers outcomes similar to normal neural network teaching. ReLoRA takes advantage of a total-rank teaching warm commence equivalent to the lottery ticket speculation with rewinding. With the addition of a merge-and-rein-it (restart) technique, a jagged understanding price scheduler, and partial optimizer resets, the performance of ReLoRA is enhanced, and it is introduced nearer to whole-rank instruction, specifically in large networks.
They check ReLoRA with 350M-parameter transformer language models. Even though testing, they concentrated on autoregressive language modeling due to the fact it has tested applicable throughout a wide vary of neural community utilizes. The success showed that ReLoRA’s efficiency grows with product sizing, suggesting that it could be a excellent preference for teaching networks with numerous billions of parameters.
When it arrives to coaching major language products and neural networks, the researchers really feel that acquiring very low-rank teaching strategies offers sizeable assure for boosting education performance. They imagine that the local community can learn much more about how neural networks can be properly trained by means of gradient descent and their extraordinary generalization expertise in the over-parametrized domain from lower-rank coaching, which has the probable to contribute considerably to the improvement of deep learning theories.
Look at out the Paper and GitHub link. Don’t overlook to join our 26k+ ML SubReddit, Discord Channel, and Email E-newsletter, where by we share the most current AI research information, amazing AI jobs, and much more. If you have any questions regarding the higher than short article or if we missed anything at all, experience no cost to e-mail us at [email protected]
🚀 Examine Out 800+ AI Resources in AI Resources Club
Dhanshree Shenwai is a Laptop Science Engineer and has a fantastic encounter in FinTech organizations covering Fiscal, Cards & Payments and Banking area with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving planet making everyone’s life straightforward.
[ad_2]
Supply backlink