

[ad_1]
I not too long ago posted a blog about the prior weblogs I’d composed about SD-Obtain/DNA Heart structure and some implementation facts. My intent there and in this blog site is to update y’all with some far more the latest discussions I and other folks have been having.
A lot more a short while ago, I/we also posted an update about SD-Obtain (“SDA”) Web sites.
1 other topic seems to keep coming up, both equally in an SDA context and in a common context: the Internet relationship, which every person appears to do differently. And in some cases badly if the intent is High Availability (“HA”). Perhaps we should call it “The Kluge Zone” (with eerie new music accompanying it).
For SDA, this can be a deep style matter if you are working with SDA Transit.
Solitary exit is fairly basic. It has to be. LISP will supply what quantities to a default route stating, in influence, “to go away SD-Obtain land, tunnel site visitors to this Border Node (or HA pair).” That tunnel frequently terminates in the info middle in quite close proximity to your World-wide-web exit route. If your data heart has other things (like a internet site or two) concerning it and the Online exit, that might will need more thought. That problem tends to be uncommon (or I’d like to assume so). And the issues explained down below even now implement. With SDA Transit, you even now get to decide one or extra default exits, which could possibly be your World-wide-web blocks or your info centre blocks, but it simply cannot be each.
When you have two websites giving Web exit, points get more demanding. If you want failover, there are some simple but non-apparent ways to create it.
A characteristic I’d very long awaited from Cisco termed “border prioritization” was built but reportedly has been buggy for a though. The idea (as I understood it) was to be ready to specify the border internet site you prefer for Net egress, with failover to the other web-site. The last I listened to was get the job done is currently being finished to deal with that and that a function identified as community around-journey could be coming faster that may possibly be relevant. The two functions do not come up in Google or Cisco search, presumably because not formally supported nonetheless. You are going to need to speak to Cisco SDA specialists if possibly of these options sound intriguing or essential for your style. I’m undoubtedly in no posture to chat about internal Cisco operate in progress.
Late update: Cisco HAS been speaking, e.g. at Amsterdam, about a precedence attribute: consider general main and fallback exits.
Since this was to start with drafted, I’ve found out about a brand-new Cisco element for SDA referred to as “Affinity”. It was evidently announced in October 2022 and was apparently much too new for CiscoLive Amsterdam. I’ll write-up a different weblog about it as a abide by-on to this one. If this is urgent for you, speak to your Cisco TME.
So, what can you do with very well-set up and familiar, reliable technology?
How Do I Aid Dual Exits?
All is not lost!
With a modicum of high-speed interconnection, you can get a substantial degree of multi-internet site higher availability quite only.
The simplest respond to is arguably to run IP Transit. AKA “VRF-Lite on all underlay links”. Not way too negative if you have only 2-4 VNs/VRFs. Messy if you have a lot more.
What that buys you is the ability to decide on which prefixes and metrics to use to direct targeted traffic to wherever you want it. I like BGP for that, myself. Url point out protocols like OSPF and IS-IS make targeted visitors engineering a bit more durable.
Dual Exit Diagram
Listed here is a new, improved variation of a diagram I have made use of right before, built specially to focus on this situation.
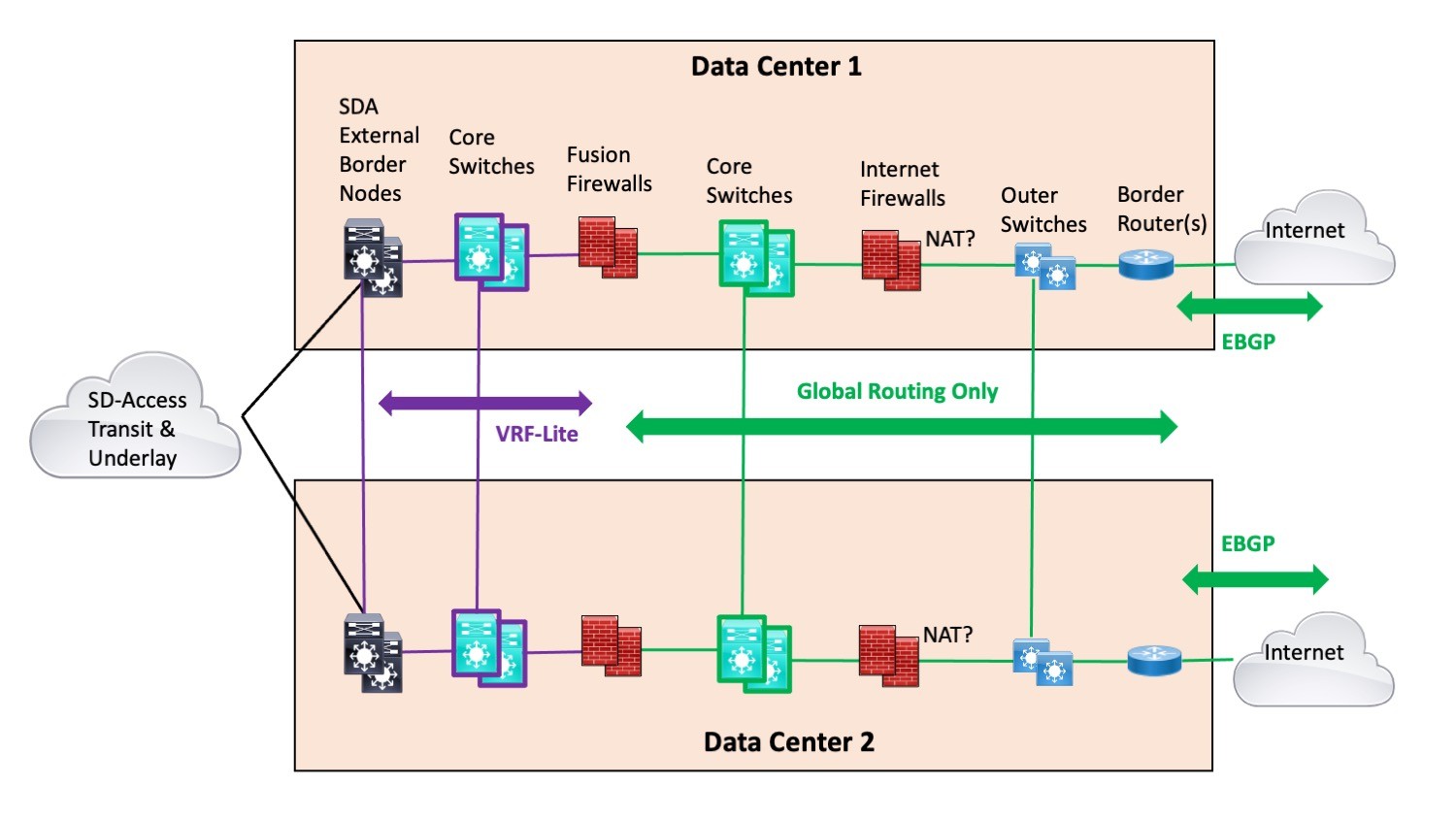 Note: I drew one traces to lessen clutter. In actuality, the vertical pairs at the two web sites would be related by two or four cross-back links (“rectangle or bowtie”). For that make any difference, the horizontal back links (strains in the diagram) would also be two or 4 links.
Note: I drew one traces to lessen clutter. In actuality, the vertical pairs at the two web sites would be related by two or four cross-back links (“rectangle or bowtie”). For that make any difference, the horizontal back links (strains in the diagram) would also be two or 4 links.
The notion is to run SDA Transit into two pairs of “External Border Nodes”. A person pair in every of the two data centers: proven on the still left previously mentioned. The purple highlights wherever VRF-Lite is working (or “IP transit” – I prevent that time period for this localized case because it looks to include unnecessary obscurity). The VRF-Lite runs into the still left side of the Fusion Firewalls (“FFWs”). Almost everything in the FFWs and to their correct is world-wide routing only.
The purple main switches are just VRFs on the same bodily switches that are revealed with environmentally friendly highlights. Or they can be separate switches if that makes you come to feel better, you want simplicity, or you like contributing to Cisco’s bottom line.
I draw the diagram this way given that almost everything else I’ve tried using ends up with triangles in it or just looks weird. (E.g., stacking the purple and environmentally friendly main switches in the diagram.)
Why do it this way?
Very well, the critical level is that it de-partners the SDA community from the firewalls and edge. In essence, SDA Transit will get your website traffic to a person of the information facilities, and if there is a firewall difficulty, you can shunt the targeted traffic to the other info heart, and back if vital/ideal.
The design problem at engage in here is preserving firewall condition for flows and return targeted visitors. In particular very long-lived flows.
For this layout, I would operate BGP on the FFWs, so that if there is a trouble, routing on the two remaining and suitable sides will shift stateful targeted visitors to the other internet site. (Specifics remaining to the reader.)
You then have the choice of jogging with a chosen web page or not. Considering that the FFWs can demand a large amount of potential, they might be expensive, which will produce the urge to use them. If you opt for to do that, you have all the normal routing instruments to function with, somewhat than acquiring to depend on SDA characteristics that may perhaps not exist or are new and quite possibly buggy.
LISP Pub/Sub
My knowledge is that SDA LISP Pub/Sub at current presents you the potential to designate World wide web exits, and round-robins if there are many this kind of web-sites.
The previously mentioned design with its decoupling lets you have dual web-site HA and “fix” the routing to do what you feel you require. Solitary desired exit for simplicity, or dual with far more complexity.
About the FFWs
It would seem like I should incorporate a reminder about what the FFWs are there for.
Their most important reason is to management traffic likely involving VNs/VRFs. That is presumably why you designed the VRFs in the very first area: you wanted to isolate attendees, IOT, PCI traffic, no matter what.
The 2nd objective is as a person probable issue to control user to server access, a prevalent need unless of course you’re it’s possible doing ACLs in some variety in VMware NSX. Or significantly less typically, ACI. That is also almost certainly how you filter server to server flows.
Typically, internet sites I’ve seen presently have an outdoors firewall pair, managing server to World-wide-web site visitors, and ordinarily consumer to Online as well.
Failure Modes
Assuming acceptable routing, and so on., a solitary machine failure or single hyperlink failure should not be a problem. There’s a Lot of redundancy there!
Let us study some failure modes.
- External border pair failure or slash off from underlay at one web site.
IP Transit or LISP Failover would be essential. IP Transit would be your common IGP or BGP failover.
LISP devoid of Pub/Sub seemed to NOT are unsuccessful more than, or at least only extremely gradually, the very last time I analyzed it. LISP Pub/Sub is new considering that the very last time I had the chance to do tests.
- Border pair to FFW, FFW, or FFW to main switches failure.
With dynamic routing (with the FFW collaborating), visitors ought to go via the other info centre. If you have a most well-liked exit by using the Net at the knowledge heart with the failure(s), visitors should really go back throughout the crosslink, and many others. (Sub-exceptional, but beats participating in games with, or waiting for Web failover?)
And if you look carefully, the complete FFW block tale gets to be the exact same as the core switch/World wide web firewalls/outer switches (or routers) tale, as considerably as routing and failover.
In small, this approach de-partners how the packets get to one of the knowledge facilities (IP Transit or LISP-based SDA Transit) from the whole firewalling and World-wide-web routing situation. Which is a good matter. Modular style, reduced complexity.
But!
Observe that the previously mentioned assumes the two exits are relatively nearby, so that latency is a non-concern. If they are far aside, then you’ll probably want spot-mindful exit priorities, which is a summary of what Affinity can do.
What I cannot easily notify you how to do is get hold of load-sharing throughout exit complexes. The obstacle to load-sharing is preserving firewall point out. Coverage routing centered on source IP block seems like it may possibly be turned into a workable option.
If you’re inclined to do cross-site firewall clustering, then stateful return paths is no massive challenge. I’m video game for localized firewall clustering, but cross-internet site clustering strikes me as including complexity and risk (new failure modes) rather than escalating availability.
Yeah, it would allow for use of the secondary internet site equipment and backlinks, neither of which is likely reasonably priced.
Disadvantage: if the cross-back links fail between websites, you continue to have a dilemma. Place in different ways, introducing cross-website failover to a routing scheme that makes use of both equally World wide web exits statefully provides yet another increment of complexity. Do you definitely want to go there?
Late Observe: Affinity would seem to aid address this!
Versions on This Concept
Static routes – just say no.
If you use public addressing internally and do NAT on the firewalls, to two distinct public blocks that are externally marketed (i.e. 2 x /24 at a least), then that most likely simplifies state preservation. Advertising and marketing a /23 and one of the /24s out of just about every web-site might be handy in that situation.
I don’t have any other concepts at the instant. Primarily ones that stay away from complexity.
Require Extra Handle?
It’s considerably less tasteful, and in all probability far more configuration perform, but IP Transit could be a critical consideration right here. Particularly if you never assume to have much more than a pair of VNs (VRFs) in your SD-Accessibility network. (Be absolutely sure, since later on on changing from IP Transit to SDA Transit looks like it would be unpleasant?)
What that purchases you is a even bigger established of routing applications for which site visitors goes wherever.
Summary
I hope this will get you wondering about your Net exits and redundancy, and what your failover approach is.
I have seen a good deal of designs wherever World-wide-web dual-internet site automated failover has not been applied, or only works for some failure modes. Also, I and many others used to not have confidence in dynamic routing on firewalls (or not have confidence in the firewall admins), possibly owing to painful CheckPoint experiences. But all that may well have transformed without having us noticing!
Many thanks to David Yarashus and Mike Kelsen (and J.T.) for discussions and insights about this subject.



[ad_2]
Resource link