
[ad_1]
Reinforcement discovering gives a conceptual framework for autonomous agents to understand from working experience, analogously to how one could possibly coach a pet with treats. But simple applications of reinforcement studying are often far from natural: instead of using RL to discover via demo and mistake by basically making an attempt the desired task, normal RL programs use a separate (commonly simulated) schooling period. For instance, AlphaGo did not master to participate in Go by competing in opposition to countless numbers of human beings, but rather by actively playing from itself in simulation. While this kind of simulated teaching is pleasing for game titles in which the guidelines are beautifully regarded, implementing this to genuine entire world domains these as robotics can have to have a variety of intricate methods, these kinds of as the use of simulated information, or instrumenting serious-planet environments in many techniques to make training possible less than laboratory circumstances. Can we alternatively devise reinforcement understanding units for robots that let them to find out right “on-the-job”, while undertaking the endeavor that they are required to do? In this weblog article, we will focus on ReLMM, a process that we created that learns to clear up a space immediately with a real robot by way of continuous discovering.




We examine our method on distinct tasks that selection in problem. The best-left activity has uniform white blobs to pickup with no obstacles, while other rooms have objects of numerous designs and colors, road blocks that increase navigation difficulty and obscure the objects and patterned rugs that make it hard to see the objects versus the floor.
To help “on-the-job” teaching in the genuine earth, the issue of collecting more encounter is prohibitive. If we can make teaching in the actual planet much easier, by creating the details accumulating system extra autonomous with no necessitating human checking or intervention, we can further benefit from the simplicity of brokers that study from encounter. In this get the job done, we style and design an “on-the-job” mobile robot education process for cleansing by learning to grasp objects all through various rooms.
Folks are not born one particular working day and performing task interviews the upcoming. There are quite a few degrees of responsibilities men and women understand ahead of they implement for a position as we start off with the easier kinds and build on them. In ReLMM, we make use of this thought by allowing for robots to coach typical-reusable expertise, this sort of as greedy, by first encouraging the robot to prioritize instruction these competencies before learning afterwards capabilities, these types of as navigation. Learning in this style has two pros for robotics. The very first edge is that when an agent focuses on finding out a talent, it is a lot more efficient at amassing data around the community condition distribution for that skill.
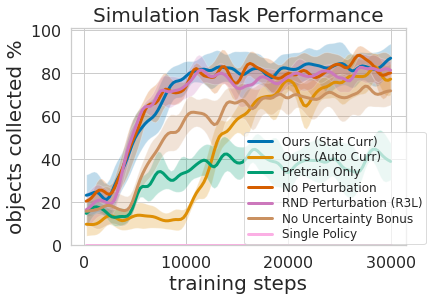
That is revealed in the figure above, where by we evaluated the amount of money of prioritized grasping encounter essential to consequence in economical mobile manipulation instruction. The second benefit to a multi-degree finding out method is that we can inspect the types educated for diverse duties and request them queries, such as, “can you grasp nearly anything ideal now” which is useful for navigation schooling that we explain upcoming.
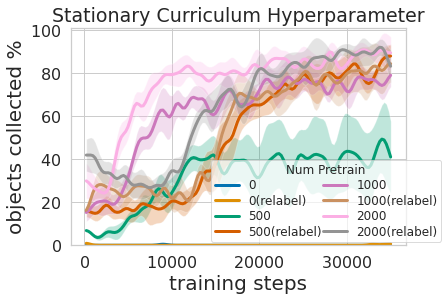
Education this multi-amount policy was not only more productive than understanding the two expertise at the very same time but it allowed for the greedy controller to notify the navigation plan. Having a design that estimates the uncertainty in its grasp success (Ours earlier mentioned) can be made use of to boost navigation exploration by skipping places without graspable objects, in distinction to No Uncertainty Reward which does not use this details. The model can also be utilised to relabel information during instruction so that in the unlucky situation when the grasping model was unsuccessful seeking to grasp an item within just its reach, the grasping coverage can nonetheless offer some signal by indicating that an item was there but the grasping plan has not yet acquired how to grasp it. What’s more, studying modular types has engineering added benefits. Modular instruction enables for reusing skills that are much easier to master and can permit developing clever systems one piece at a time. This is beneficial for many factors, which include protection analysis and being familiar with.
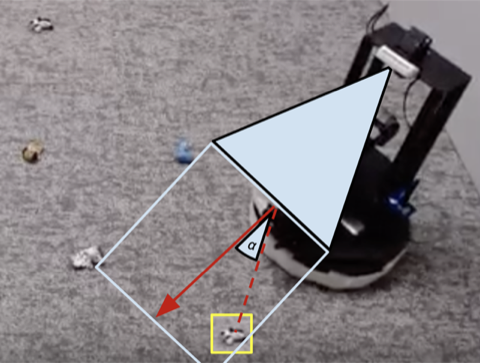
Many robotics responsibilities that we see today can be solved to different stages of success applying hand-engineered controllers. For our room cleansing task, we created a hand-engineered controller that locates objects employing picture clustering and turns in direction of the nearest detected object at every single phase. This expertly intended controller performs extremely very well on the visually salient balled socks and normally takes fair paths about the obstructions but it can not understand an optimal path to gather the objects swiftly, and it struggles with visually assorted rooms. As proven in video clip 3 down below, the scripted coverage receives distracted by the white patterned carpet even though trying to identify extra white objects to grasp.
1) 
2) 
3) 
4) 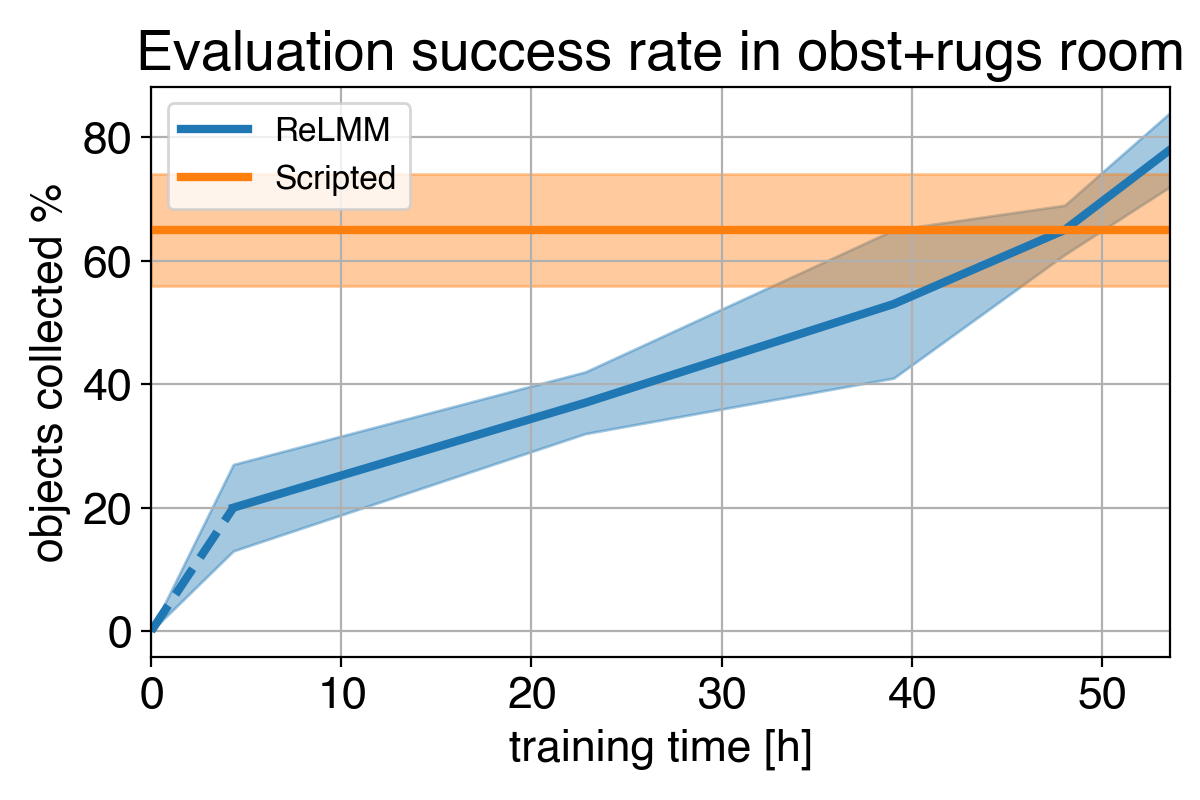
We present a comparison among (1) our coverage at the commencing of training (2) our policy at the stop of education (3) the scripted policy. In (4) we can see the robot’s effectiveness make improvements to above time, and sooner or later exceed the scripted policy at quickly amassing the objects in the room.
Given we can use experts to code this hand-engineered controller, what is the intent of studying? An significant limitation of hand-engineered controllers is that they are tuned for a certain endeavor, for instance, grasping white objects. When numerous objects are launched, which differ in colour and shape, the primary tuning could no extended be best. Fairly than demanding even further hand-engineering, our studying-centered technique is able to adapt by itself to numerous responsibilities by gathering its own practical experience.
Having said that, the most critical lesson is that even if the hand-engineered controller is able, the learning agent ultimately surpasses it supplied plenty of time. This learning procedure is itself autonomous and normally takes put even though the robotic is executing its job, earning it comparatively reasonably priced. This displays the capacity of learning agents, which can also be imagined of as performing out a standard way to complete an “expert guide tuning” system for any variety of task. Finding out methods have the potential to create the entire command algorithm for the robotic, and are not confined to tuning a few parameters in a script. The crucial phase in this operate will allow these authentic-globe studying devices to autonomously accumulate the facts needed to enable the success of discovering solutions.
This write-up is primarily based on the paper “Fully Autonomous True-Earth Reinforcement Learning with Apps to Cellular Manipulation”, offered at CoRL 2021. You can obtain far more information in our paper, on our website and the on the video clip. We deliver code to reproduce our experiments. We thank Sergey Levine for his beneficial opinions on this blog site post.
[ad_2]
Resource hyperlink